Challenges Before Machine Learning
Machine learning is a field that is constantly developing and in great demand. It uses already-processed data to produce real-time outcomes without any human involvement. Creating models that are driven by data, it generally makes it easier to study and evaluate enormous amounts of data. Machine learning is now a quick and effective approach for organizations to create models and develop strategies.
One might even conclude at some time that machine learning models are relatively easy. But the truth is different. The discipline of data science that encompasses machine learning is incredibly complex, and there are still a number of major challenges that are to be dealt with and need to be resolved in the future. Let’s try to understand these challenges.
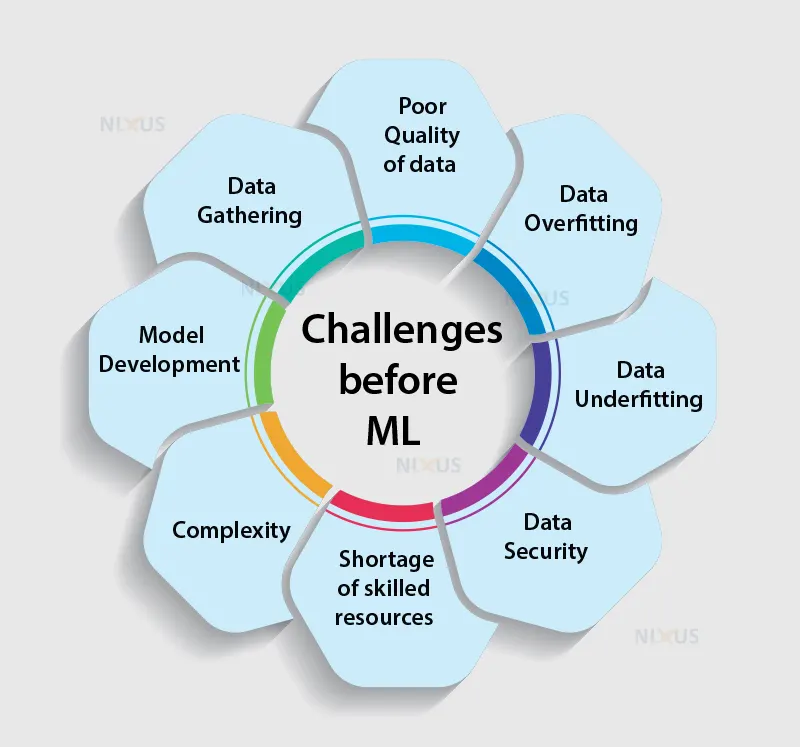
Challenges Before Machine Learning
1. Data Gathering
Any use case relies heavily on data. Data scientists spend 60% of their time gathering data. Beginners may quickly find data from Kaggle, the UCI ML Repository, and other sources to practice with machine learning.
But the scenario is different to conduct real-world case studies. Data must be obtained from clients to solve business challenges ( to collect data requires coordination of ML engineers and experts of the domain) or be scraped from websites.
After the data has been gathered, it needs to be organized and stored in a database. This necessitates an understanding of big data (or data engineering), which is vital in this situation.
2. Data of poor quality
The absence of high-quality data is the main issue that machine learning is facing. While improving algorithms frequently takes up the majority of developers’ time in AI, it is crucial that the data is of high quality for the algorithms to perform as expected.
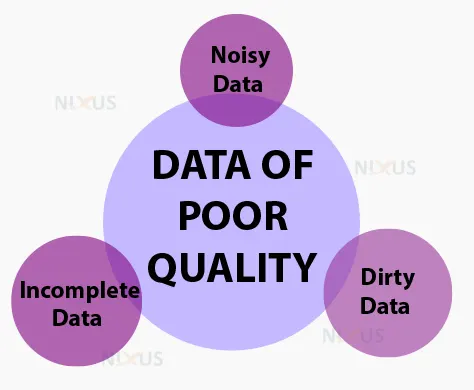
The common archenemies of perfect machine learning are dirty, noisy, and incomplete data. Prior to beginning, one has to take the time to carefully examine and scope data using data governance, integration, and exploration until one has clear data as the solution to the problem.
3. Data Overfitting
Data overfitting is the process of creating a machine learning model that is too complex and attempting to fit it into a small collection of data. In human language, it could be a situation when a person after receiving a defected item from an online shopping website thinks that every shopping site has defected items. This person with this type of conclusion has clearly been trapped in an overgeneralization condition. This type of condition tends to occur in machine learning as well and is called data overfitting.
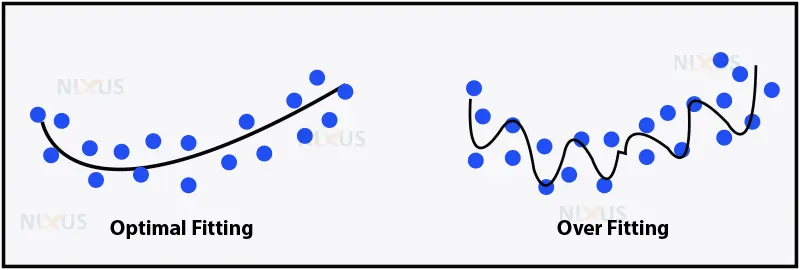
4. Data Underfitting
Underfitting, the inverse of overfitting, occurs when the model designed is too simple to understand the underlying structure of the data. It’s like trying to get into a pair of oversized pants. It usually occurs when there is insufficient information to build the exact same model and with the use of non-linear data, one tries to construct a linear model.
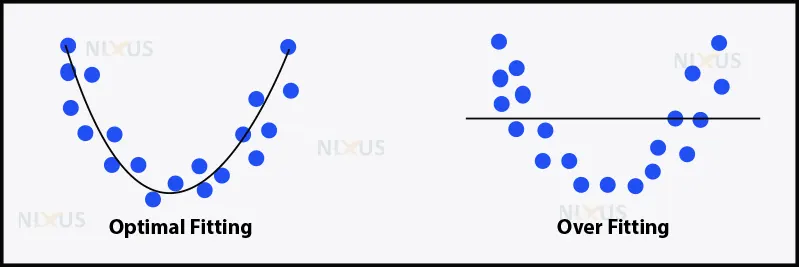
Simply, the only solution for dealing with both of these issues (underfitting and overfitting) is to create an algorithm that is built solely for a specific function. There will be no copying and pasting here. Everything must be customized to your project.
5. Data Security
Data security is another frequently encountered challenge in machine learning. After obtaining the data, security is a critical consideration that must be addressed.
It is critical to distinguish between data of sensitive and insensitive nature in order to implement machine learning in a correct and efficient manner. Another issue with data security is fake data. This issue arises when an organization is attacked by attackers who substitute real data with fake data.
Another issue related to data security is access control. Here, designing encrypted authentication and validation processes is the best way to prevent needless complications because users must be verified before they can make any changes to the system or the data it stores.
6. Model Deployment
Even though it sounds strange, most time machine learning experts have trouble deploying their projects correctly. People who deal with Machine Learning occasionally have trouble comprehending business issues.
By the time an organization decides to upgrade to machine learning, they frequently already have analytics engines in place. It is challenging to incorporate more recent Machine Learning techniques into more established techniques. Implementation is greatly facilitated by maintaining accurate interpretation and documentation. Implementing features like anomaly detection, predictive analysis, and ensemble modeling can be made considerably simpler by working with an implementation partner.
7. Complexity
Even though Artificial Intelligence and Machine Learning are in high demand, most of these fields are still in the experimental stages and are actively using the trial-and-error approach. The procedure is extremely complicated and time-consuming, from system setup to instilling complex data and even coding. It is an arduous procedure that does not allow for any errors or mistakes.
Putting machine learning into practice is much more difficult than doing typical software development. Usually, there are many unknowns in a machine learning project. It entails collecting data, processing it to train algorithms, engineering those algorithms, and then these are trained in order to learn from the data in a way that supports your business objectives.
It necessitates extensive planning and meticulous execution. However, there is no guarantee that the time your team estimated for finishing the machine learning assignment will be accurate due to the multiple layers and the typical uncertainties in the behavior of the algorithms. Therefore, when working on ML projects, it is crucial to be patient and take an experimental approach. The project and the team should be given plenty of time if you want the adoption of machine learning to produce the desired results.
8. Shortage of skilled resources
Another problem with machine learning is that deep analytics and ML are still comparatively recent technologies. Machine learning experts are needed to maintain the process from the initial start code to the maintenance and surveillance of the process.
The markets for artificial intelligence and machine learning are still developing. It is challenging to locate sufficient human resources. As a result, there aren’t enough talented people available to create and handle scientific materials for ML. Data scientists frequently require a combination of space expertise as well as an in-depth understanding of mathematics, science, and technology.
Conclusion
So, it is clear that despite being a fantastic technology, machine learning still has a lot to accomplish. There are many different types of machine learning challenges that have been discussed in this blog. Some of them have to do with the data that all machine learning models use as their starting point. Some of them have to do with concepts of machine learning, like data security. And lastly, some of them make reference to implementations that we are still working to perfect. To advance the development of this technology, there are some major obstacles that are to be overcome.