Machine Learning Projects – Innovative Ideas to Boost Your Resume
Ambitious ML engineers are eager to work on ML projects but find it difficult to develop creative ideas. Finding ML project ideas that fascinate and motivate you is crucial, especially when you are a beginner.
To begin with, there are four significant requirements for the ML project.
I. Area of your interest
II. Choosing the suitable dataset
III. Dataset size
IV. The complexity level of the dataset
To make your ML career brighter, some unique and cutting-edge ML project ideas must be adopted. But don’t worry! We are here to help you find it easy to pass through this step of thinking of some innovative ML project idea. So let’s begin with the same.
Some Machine Learning Projects
1. UBER TRIPS
In this project, data is taken from Uber trips, as everyone uses cabs to commute from one place to another, and Uber is one of the most trusted brands. Many patterns can be drawn from this data, such as rate per km, highest and lowest trips taken, the busiest hour of the day, competition between the cab fares of other companies, etc. The dataset used here is based on New York City- one of the busiest and most complex cities in terms of transportation. New York is home to 84.7 lakh people as of 2021, and on one hand, it has every facility (like Uber), while on the other, it is one of the most expensive cities.
This dataset shows about 4.5 million Uber pickups in the city from April to September and 14.3 million from January to June 2015. Based on the same data, several patterns can be drawn, such as the number of luxury cars ordered, the most followed route and the number of cab rides shared.
2. Netflix recommendation
Whenever you open Netflix, it shows programs similar to your watch history. For example, if you have recently watched any k drama, it will suggest other k dramas, saying you might like this. This way, Netflix personalizes your Netflix experience by applying a convolutional neural network that interprets visual imagery.
Netflix Heavenly depends on “contextual bandits,” which help decide which type of content gets the most engagement based on the user’s history.
3. Insurance prediction with Machine Learning

This is something prevalent like every insurance company maintains data where they keep a record of who they have contacted to promote the insurance service (Whenever one gets a call from some sales agent selling insurance, they maintain primary data where they keep basic information like name, age, income etc.) Now, the company will filter the data and focus on those who have the potential to buy insurance; this not only saves time but also saves the company’s resources. By potential customer, it means that if you’re trying to sell travelling insurance, you’ll sell it to someone who travels a lot. This method is called insurance prediction, which benefits the insurance industry.
4. Unemployment Analysis System

Thousands of people lost their jobs during the pandemic, and this data set will measure the unemployment rate. Unemployment means not being able to find a job or a stable income source. The unemployment rate in India rose to 20.9% from April to July 2020. The unemployment rate is measured by the number of people unemployed divided by the working population or people working in the labor force. The project analyzes state-wise unemployment in India during the pandemic, measuring the unemployment rate of Delhi in 2020 using this data.
5. Car price prediction

When buying a car, people take a lot of factors like brand, budget, mileage, horsepower, etc. Predicting the price of the vehicle based on the features mentioned above is one of the most essential parts of the research. The dataset used in this project is downloaded from Kaggle, and it contains all the features that contribute to deciding the price of the car. It contains simple things like brand, space, design, budget, and technical stuff like mileage, performance, fuel economy, comfort and safety, and after-sale and service costs.
6. Social Media Followers prediction

Social media is a new world where people post, interact and entertain themselves. Social media followers who have subscribed to a particular account will receive all its updates in their feeds. It is tough to predict the increase and decrease in social media followers. Professionals must use a data set to track people’s social media activity. Generally, one will rely on the data provided by social media sites like Instagram and Facebook. Still, they don’t readily provide the data, so we need different sources from which to gather such data with information like what type of post has the maximum traction.
For example, a beauty blogger will have maximum traction on posts like best moisturizers. This social media prediction project is crucial for content creators and businesses as it helps them understand what their audience will like and will not like.
7. TED TALKS recommendation system

Ted talks are recorded public speaking presentations set initially to motivate people with their life stories or powerful discussions. It is a good source from where one can learn and get inspired. The project is based on the Ted Talks recommendation system, which is entirely based on content rather than the user’s data. As a user, we will watch Ted talks on YouTube and many other videos for entertainment purposes; hence, we cannot draw user-based data on this.
The concept of cosine similarity, which is used in machine learning, is used by integrating Python, and then a system where Ted talks will be recommended is created in this project.
8. WhatsApp group chat analysis

In this project, WhatsApp group chats are being examined using machine learning and data science. After the project, the participants will receive a chat that doesn’t need to be cleaned or prepared before use. However, they will need to make sure that the data available for use has the format of the date and the time of the messages modified before they begin the project, and it is straightforward to do.
9. Profit Prediction

Companies can forecast future earnings and boost revenue by using a predictable revenue model. Understanding the organization’s historical average revenue can help you determine how you can make these improvements as we advance. In this project, for instance, the profit prediction is applied to return on advertising in multiple scenarios. The model depicts the revenue flow from customer interaction at the top of the funnel while accounting for the initial marketing expenditure.
10. Predict Credit Default-Credit Risk Prediction Project
The risk a lender assumes that a borrower won’t make the necessary payments on a debt obligation, such as a loan, a bond, or a credit card, is known as credit default risk. In almost all types of loan arrangements, lenders and investors are vulnerable to the risk of default. A credit analyst obtains and examines financial information on loan applicants, such as their payment histories, incomes, savings, and spending patterns. Still, we use machine learning to predict this nowadays as they are time efficient and leave no room for error.
In this project, the machine learning algorithm is used to predict whether the borrower will get a loan or the parameters of being a defaulter.
11. Plant species Identification

The use of image-based techniques is thought to be a promising strategy for identifying species. A landscape or garden plant must be recognized by one or more qualities, including size, form, leaf shape, blossom color, odor, etc., and these characteristics must be linked to a name, either a common or purported scientific name. A user can use the built-in camera of a mobile device to take a picture of a plant in the field and analyze it using a recognition program loaded on the device to identify the species or, if that is not possible, at least receive a list of potential species. Additionally, non-professionals can participate in this process by employing a computer-aided plant identification system.
12. Netflix stock price Prediction

One of the most well-known OTT streaming services is Netflix. It provides a sizable selection of movies and television shows and produces its work, dubbed Netflix Originals. As one of the best methods for regression analysis and time series forecasting, the LSTM neural network can be used to anticipate Netflix stock values using machine learning.
Due to their popularity, firms like Netflix are frequently monitored by investors who are quite active in the stock market. This project analyzes fluctuations in Netflix’s stock price based on its popularity of content.
13. Music recommendation System
When one uses any app like Spotify to listen to music, it creates a personalized experience for you. If you hear a song by Adele, it’ll suggest a playlist with her most hit songs. Using real datasets, this project will create a music recommendation engine. It will use the Million Songs Dataset, a dataset obtained from the outside that consists of two files: triplet_file and metadata_file. The triplet_file contains information on the identity of the performer or band, the song’s title, and how long the song is. With a listener’s playlist as the source, it may genuinely comprehend their musical preferences and identify the elements most helpful in gauging their interests and tastes.
14. Mobile Price Classification
The smartphone we use daily is perhaps one of the fastest-selling products. Our smartphones are used daily to accomplish tasks and have a short lifespan. There are a few things to consider before purchasing a new smartphone if you are currently in the market for one, like processor, performance, RAM, etc.
A model called Mobile Price Classification was created and trained using a data set received from Kaggle and based on the Multilayer Perceptron Topology. This paper introduces a machine learning project that uses Python to classify the price range of mobile devices using a pricing classification model.
15. Loan eligibility Prediction

This project is based on forecasting loan eligibility using several ML techniques. To determine loan eligibility regarding the loan sanctioning process, a dataset with gender, marital status, education, number of dependents, employment status, income, co-applicants income, loan amount, loan tenure, credit history, existing loan status, and property area is used.
This project combines Python and SQL to develop a predictive model on the Google Cloud Platform to identify whether a loan application is eligible. This application is functionally sound and complies with all banker specifications.
16. Hotel reviews Sentiment Analysis System

To rate a hotel on a booking website, guests must give their opinions about their experiences. They are nothing more than comments made by visitors regarding what they liked and did not like about your establishment. Many hoteliers examine reviews that have been collected from several platforms. Developers can categorize hotel reviews submitted by customers from the most prominent travel sites using sentiment analysis and machine learning algorithms. Numerous methods, like Naive Bayes, SVM, logistic regression, and many more, can be used with an ensemble learning model to integrate five classifiers and produce acceptable results. One can gather the necessary hotel review sentiment analysis system from Kaggle and many other locations to acquire information about hotel services during vacations and business travels.
17. Heart disease prediction

Heart disease is a general phrase that covers a variety of cardiac issues. Another name for it is cardiovascular disease. Although there are many different types of heart disease, like coronary heart disease, stroke, etc., they can be prevented and managed. Heart disease is one of the primary causes of death across the world. The healthcare industry worldwide can benefit greatly from this machine learning project’s ability to anticipate cardiac disease and effectively save lives. Numerous machine learning methods, including neighbors classifier, decision tree classifier, support vector classifier, and random forest classifier, are used in the project to detect heart disease. To compare the final model efficiently and effectively, one can utilize various libraries for a better grasp of the data and multiple numbers of algorithms to alter their various parameters.
18. Fake news detection system

False or misleading information that passes for news is called fake news. Fake news typically falls into one of two categories: Deliberately fake stories are those where the people distributing them know they are false but publish them anyway, or those with some truth that is generally false. Through news detection techniques for several datasets, this machine learning project aids in exploring various machine learning functions. Multiple forms and topics must be covered for this false news-detecting effort. To extract helpful post features on various social media platforms, relevant data is used to analyze multiple viewpoints, world events, etc.
19. Google Play Store Sentiment Analysis System
Sentiment analysis is the process of categorizing customer reviews and comments as either positive, negative or occasionally neutral. To determine what their customers want from them, most firms examine their customers’ opinions about their goods and services. With millions of apps and their reviews available on Google Play, analyzing the sentiment of available apps will be an excellent use case for sentiment analysis. The dataset is taken from Kaggle, and three new columns are needed for a better understanding of the sentiments of each customer review categorized as positive, negative, and neutral.
20. Image Filtering

One can improve a picture’s borders and lessen its noise by using image filtering. Nearly all cell phones employ this technology. Although object detection, face recognition, and other computer vision tasks can be aided by enhancing an image utilizing image filtering algorithms.
The mean filter blurs an image to reduce any noise. The n×n technique establishes the mean of the pixels, which is then used to replace the intensity of the pixels. As a result, some of the image’s noise is reduced, and the image’s edges are also improved.
21. Emojify

A tiny icon known as an emoji is used to depict an emotion, a symbol, or an item. Emojis are frequently used in communication systems, including text messaging and social networking apps. They are called nonverbal cues; these days, people can’t chat without them. The amount of data science research on emoji-driven storytelling has also increased. Now that machine learning and computer vision have advanced, it is possible to identify human emotions from images. This project categorizes human facial expressions to filter and map corresponding avatars or emojis.
22. Deepfake detection
Deep generative techniques are used to manipulate the appearance of the face in deepfakes. Deepfakes use potent machine learning and artificial intelligence techniques to edit or synthesize visual and audio information that can more readily fool, even though producing fake content is not new. Deepfakes can be produced using machine learning methods like a generative adversarial network (GAN). Deepfake video detection can be done using discriminative models. Two neural networks collaborate to create artificial images that look real and have never been seen before. This technique, generative adversarial networks (GANs), is used to train generative models. The initial network, called the “generator,” produces fresh fakes. The “discriminator,” or second network, aims to determine whether the photos are real or phony. Utilizing adversarial learning methods, the discriminative model can be used to identify deep fake films.
23. Currency exchange rate prediction

A currency’s relative value expressed in terms of another currency (or collection of currencies) is called an exchange rate. Exchange rates change often due to supply and demand. Therefore, forecasting currency exchange rates has various benefits for individuals and nations. The regression problem in machine learning is predicting currency exchange rates in this project. Every day, exchange rates change, impacting a country’s economy and an individual’s or business’s income. One can utilize various machine learning methods to anticipate future currency exchange rates. Artificial neural networks are another option for this purpose.
24. COVID-19 detection

The COVID-19 pandemic threatened human life, health, and productivity, disrupting human lives, finances, and the country’s economy. AI is crucial to classifying COVID-19 cases since it allows us to forecast infectious and recovery rates using chest x-rays and machine learning models on COVID-19 case data. Patient privacy is violated when private patient data is accessed, and training a standard machine learning model necessitates accessing or uploading all of the data. As federated machine learning offers a practical solution for data privacy, centralized computation, and high computing capacity, interest in it has grown over the past few years.
25. OLA Bike Ride Request Demand Forecast
Ola Cabs started in the Indian market; the start-up was inspired by Uber Cabs and brought cab culture to India. The Ola service industry has grown tremendously in the last couple of years and is expected to grow. People have frequently encountered issues with taxi booking requests, which occasionally cannot be completed, or the wait time for the trip’s arrival is very long due to the lack of a nearby Ola. This project examines how Ola drivers must decide where to wait for passengers so that they may be contacted quickly.
26. Pneumonia detection
Pneumonia is a bacterial, viral, or fungal infection that involves lung fluids and inflammation. It makes breathing difficult and can result in fever, a cough with yellow, green, or bloody mucus, and other symptoms. A chest X-ray checks for lung inflammation. Pneumonia is diagnosed using a chest X-ray. You can determine whether your immune system is battling an infection using blood tests like a complete blood count (CBC).
With the ongoing development of technology, it is now possible to employ tools built on deep learning frameworks to identify pneumonia from chest X-ray pictures. The challenge would be to support the diagnosing procedure so that therapy can proceed more quickly and with better clinical results. This project uses the chest X-ray images (Pneumonia) dataset from Kaggle. Training, validation, and testing data make up the dataset. The dataset set includes 5,216 chest X-ray images, 3,875 of which reveal pneumonia and 1,341 show normality.
27. Sarcasm detection
Sarcasm is words with opposite meanings than one wants to express, often used to offend or irritate someone or for a few laughs. When describing a group of individuals that are not academically smart, for instance, saying “they’re genius” is utilizing sarcasm. Sarcasm is most frequently biting and meant to hurt. Since the dawn of language, sarcasm has been a component of it. The task of sarcasm detection involves binary classification and natural language processing. Using a dataset of sarcastic and non-sarcastic sentences, the candidates working on the project can train a machine learning model to check whether or not a sentence is sarcastic. The sarcasm detection project includes a dataset with labels that can be used to predict sarcasm in a sentence.
28. Stock price prediction

The price at which one share of a company would be purchased is known as the share price or stock price. A share’s price is not constant; it changes in response to market conditions. The method of predicting the future value of a stock traded on a stock exchange to make enormous profits is known as stock price prediction using machine learning. Machine learning is essential since many variables must be considered to anticipate stock values accurately. Professionals can utilize time-series data to treat stock data. The goal is to assess the significance of recent and historical data and identify the factors currently influencing or will soon be influencing stock prices.
29. Survival prediction on the Titanic ship
Building a machine learning model on the Titanic dataset—a dataset utilized by many individuals worldwide—is a comprehensive procedure for predicting the survival of the Titanic ship. It offers information on the Titanic passengers’ destiny and summarizes the data gathered regarding socioeconomic background, gender, age, and survival. According to this machine-learning study, approximately 60% of the first-class passengers made it out alive. Less than 30% of the third-class passengers perished, which suggests that close to half of the original Titanic passengers would have survived.
30. Billionaire analysis
A person who is a billionaire has a net worth in their home currency of at least one billion units. Cash and its equivalents, real estate, and business and personal property can all be held by billionaires. A nation’s number of billionaires can reveal much about its business climate, startup success rate, and other economic characteristics. With the aid of this initiative, participants can identify trends among billionaires from around the globe and examine each nation’s business climate. Depending on the accuracy of the country’s business environment projection, this can eventually contribute to a business’s or startup’s success.
31. Xbox game prediction
Xbox is an upcoming generation of video games that supports backward compatibility on all their systems, dating back to the first Xbox. The Xbox Series X is the most potent console currently available. It is possible to forecast users’ interests using the data supplied by internet users. With a machine learning algorithm, the data from millions of user queries provided by the consumer electronics retailer BestBuy will enable the participants to forecast which Xbox game consumers will most likely purchase.
32. Social media ads classification
To categorize social media ads, one must first analyze them to identify the most profitable and likely product purchasers. Because not all items are appropriate for the target market, this project can assist business executives in categorizing their social media advertisements to assess whether a user will purchase their product. Data regarding a product’s media advertising campaign would be included in the dataset used to classify social media ads, allowing analysts to predict whether or not the target market has bought the product.
33. Sales prediction
Estimating future sales is done through the sales forecasting process. Many organisations make sales projections to help their clients make wise business decisions and foresee short- and long-term success. The Databricks platform community edition server, which enables professionals to run their spark code on their servers for free by enrolling through email ID, is used in this project for users to implement Apache Spark Machine Learning. Additionally, several online tools could aid experts in effectively creating this project.
34. Recommendation system
A recommendation system is an algorithm created to propose or recommend items to the user based on various variables. The recommendation algorithm filters out a lot of info based on the preferences and interests of the consumers. Recommendation systems have become increasingly important with the growth of services like YouTube, Netflix, Amazon, and others. In many businesses, recommender systems are essential since they can contribute to significant income generation. This project primarily concentrates on the fundamentals of the recommendation system and provides a brief overview of the various algorithms.
35. Real-time Face mask detection
Computer vision and image processing significantly impact the identification of the face mask. Face detection has a variety of use cases, including face recognition and facial motions, where the latter must accurately depict the face. The risks posed by face mask detection technologies still seem to be successfully handled as machine learning algorithms advance quickly. This breakthrough is becoming increasingly significant as it is used to identify faces in pictures and real-time video streams. Face detection alone is challenging for the face mask detection models currently being offered, though. After the outstanding results of present face detectors, analysing events and video surveillance is a constant challenge in developing increasingly advanced facial detectors.
36. Store sales projection
Estimating future sales to inform your decisions better is known as sales forecasting. Typically, a projection is based on historical sales data, industry benchmarks, and prevailing business conditions. It’s a technique to assist you in managing your staff, ash flow, and any other resources that could impact revenue and sales. Based on past sales data, it is often simpler for well-established organizations to produce more precise sales estimates. However, to establish a baseline for sales figures, newer enterprises must rely on market research, competition benchmarking, and other sources of interest.
37. Predicting Interest levels of rental listings
There should be more involved in finding the ideal place to call your new home than simply looking through countless postings. RentHop uses statistics to rank rental postings according to quality, making apartment searching smarter. Finding the ideal apartment might be challenging enough, but organizing and programmatically making sense of all the available real estate data can be even more challenging. Everyone’s invited to participate in this hiring competition hosted by Two Sigma using information on rental listings provided by RentHop. Based on the date the listing was created and other factors, we will forecast the number of enquiries a new listing will receive. By doing this, RentHop will be better able to manage fraud control, spot potential listing quality issues and help owners and agents comprehend the requirements and preferences of tenants.
38. Customer churn prediction analysis
A customer is an individual who purchases something from a seller, vendor, or provider in exchange for cash or another valuable item. The percentage of consumers that ceased using the goods or services offered by your company over a specific period is known as customer churn. Your customer turnover rate indicates how many of your current clients are unlikely to make another purchase from your company. Five times more money is spent on gaining a new customer than keeping an old one. In this project, one can use machine learning to predict the time a customer has left with you and whether they’ll continue to work with you. If the prediction indicates that they will likely discontinue with your company, you can take the necessary measures to keep them.
39. Human activity recognition using smartphone dataset
The smartphone dataset comprises recordings of 30 people’s fitness activities using smartphones with inertial sensors.
This machine learning study aims to build a classification model to detect human fitness activities precisely. Working on this assignment will help you understand how to address multi-classification problems.
40. Driver demand prediction
The availability of drivers is essential for the effective operation of ridesharing and food delivery services worldwide. Determining the likelihood that drivers will be available in a specific area so that users can know whether or not a cab will arrive and the approximate wait time. This makes it easier to place drivers in high-demand areas efficiently. It will transform a time series problem in this project into a supervised machine learning challenge. An exploratory analysis must be done to find patterns in the time series. The Auto-Correlation Function (ACF) and Partial Auto-Correlation Function (PACF) will be used to analyse the time series. A regression model must be constructed and used to resolve this time-series issue. After it has been created, spot testing will be carried out on the training model. Following that, the ensemble models Random Forest and Xgboost will be used to anticipate the demand for drivers.
41. Market basket analysis
Market basket analysis is the practice of better understanding the combinations of different items that buyers frequently buy. It is a data mining approach used to track consumer buying habits to understand them better and, as a result, boost sales. The idea behind this is that if a customer buys a product or a group of products, let’s say product “A,” this increases the likelihood that the customer would also be interested in purchasing a second product or group of products, “B.” This is because, based on the actions of previous customers, an interest in A implies an interest in B. Market basket analysis can be utilized for cross-selling, personalized consumer suggestions, and targeted advertising. It’ll be good for the business and help the customers.
For example, if they forget to buy something, they can purchase it while looking at this analysis, like you can’t cook pasta without Italian herbs or cheese.
42. Census income dataset project
Income inequality has recently become a significant concern, and census data can be instrumental in projecting statistics like each person’s income and health based on historical records. This machine learning research aims to predict whether income exceeds $50,000 per year using adult census information and census data such as education level, relationship, hours worked per week, and other variables. The Adult Census Income dataset is intriguing due to its wealth and diversity of information, which ranges from a person’s relationship status to their degree of schooling. The Adult Census Income Dataset, which has about 32K rows and 15 columns describing different aspects of people, is a beautiful option for creating a classifier because it perfectly combines missing values, numerical data, and categorical data.
43. Speech emotion recognition
Since all we have left now is virtual contact, the pandemic has forced us to consider how emotions impact communication. Finding the right emotions becomes a monumental endeavour as a result. The Speech Emotion Recognition(SER) system, a mix of several frameworks and functions based on analyzing audio signals to identify emotions, was developed because there is no reliable method to determine the emotions from speech. The human brain generally divides speech’s acoustic, linguistic, and vocal components into three segments to isolate emotions from speech. However, in this entertaining machine learning project, we will use the acoustic aspect of speech, including pitch, jitter, tone, etc., to determine the appropriate emotion.
44. Ultrasound nerve segmentation
Having surgery is no joke. There are dangers and difficulties, not to mention the recovery period following surgery. Many patients also deal with the problem of postoperative pain. Adults’ pain is now treated with medications, each of which has a unique set of adverse effects. Instead of taking medications that will only temporarily dull the pain, ultrasonic nerve segmentation allows the cause of the discomfort to be identified and treated. To correctly implant a catheter for improved pain management, the source of the discomfort can be identified by accurately identifying nerve structures in ultrasound pictures. Since this analysis directly affects a patient and lives are at stake, the nerve structures must be examined as precisely as possible. More issues for the patients may arise as a result of errors that result in inappropriate insertion. This experiment entails collecting photographs of nerves that do not exhibit any damage to contrast them with nerves that exhibit abnormalities, which may be a symptom of discomfort. For analysis, images must be divided up into a matrix.
45. Avocado price prediction
Among millennials, avocados appear to be becoming more and more popular. According to Statista, in 2020, over 2.6 billion pounds of avocados were consumed in the United States alone, compared to just 436 million pounds in 1985. Avocados are famous for being a good source of “good fats” and are seen as a healthy food option. The goal is to forecast future costs using information on past costs related to location, weather, and the season’s supply of avocados. Price prediction based on sales would be a good market input for transferring goods to areas where the fruit is more in demand or even encouraging consumption in areas where demand is not up to par.
46. Walmart dataset for sales prediction
One of the most popular applications of machine learning for determining the variables that influence a product’s sales and anticipating future sales volume is in sales forecasting. The dataset from Walmart, which contains sales information for 98 products across 45 stores, is used in this machine-learning experiment. Weekly sales are included in the dataset for each department and store. To improve channel efficiency and inventory planning, this machine learning project aims to forecast sales for each department within each store. Working with the Walmart dataset is challenging because it contains specific markdown events that impact sales and should be considered. We can create a predictive model utilising the Walmart dataset to predict how many sales Walmart will make in the future.
47. Boston house pricing prediction
The prices of properties in various Boston neighborhoods are included in the Boston House Prices Dataset. The dataset also contains data on non-retail business sectors (INDUS), crime rates (CRIM), the average age of homeowners (AGE), and several other variables (there are 14 attributes in all). The UCI Machine Learning Repository has the Boston Housing dataset available for download. This machine learning project aims to forecast a new home’s selling price using housing price data and fundamental machine learning principles. With only 506 observations, this dataset is deemed an excellent place for machine learning newcomers to begin their practical practice with regression concepts.
48. Iris flower classification
Iris Flowers is one of the most straightforward machine learning datasets in the literature, making this one of the easiest machine learning projects. The “Hello World” of machine learning is often used to describe this particular machine learning problem. The dataset has numeric properties, therefore those new to machine learning (ML) must learn how to import and manage data. The iris dataset is modest, fitting readily into memory and starting without extra scaling or adjustments. This machine-learning project aims to categorize flowers into virginica, setosa, or versicolor species based on the size of their petals and sepals.
49. SMS spam detection
Short Message Service (SMS) has become a multi-billion dollar industry in recent years as the use of mobile phones has expanded in popularity. The cost of messaging services has also decreased, increasing the amount of spam delivered to mobile devices. Up to 30% of SMS messages in some regions of Asia were spam in 2012. The established email filtering algorithms may perform poorly in their classification due to the absence of accurate databases for SMS spam, short message lengths and features, and their informal language. This study uses accurate SMS spam databases from the UCI Machine Learning repository. Various machine-learning algorithms are used in the databases following feature extraction and preprocessing. After comparing the outcomes, the optimal algorithm for text message spam filtering is introduced.
50. Rainfall prediction
Predicting rainfall is one of the most commonly used research areas for weather forecasting because it causes significant property damage and loss of life. The complex mathematical tools utilized in earlier, widely used rainfall prediction models were insufficient for a higher categorization rate. This study proposes a brand-new, cutting-edge method for applying linear regression analysis to forecast monthly rainfall. Predictions of when it will rain are made using quantitative data about the atmosphere’s current state. Many machine learning algorithms can learn intricate mappings between inputs and outputs using only a small number of samples. Due to the atmosphere’s dynamic nature, it is challenging to anticipate rainfall accurately.
The variability in previous years must be used to anticipate rainfall in the future. The suggested model employs linear regressions and utilizes various characteristics, including temperature, humidity, and wind. Since the suggested model tends to anticipate rainfall based on the historical data for a particular geographic area, this prediction should be more accurate.
51. Water Quality analysis
Analyzing water quality is one of the critical topics of machine learning research. To train a machine learning model to determine if a water sample is safe or unsafe for eating, we must first understand all the water potability parameters. This process is also known as water potability analysis. The Kaggle dataset, which includes information on the key elements influencing water potability, is used for the water quality analysis job. Before building a machine learning model to determine if a water sample is safe for eating, one must first quickly examine each feature of this dataset because all the variables that affect water quality are crucial.
52. Grade prediction
When studying in school or college, every student is different. Although everyone is learning from the same platform, from the same teacher and given the same fees, the learning outcome is not the same. Good grades decide what the future of the student will entail. This project can forecast student performance using machine learning techniques, allowing us to assist students whose grades are anticipated to be below average. The difficulty of regression in machine learning serves as the foundation for student grade prediction.
53. Stress detection
It might be challenging to identify psychological stress because there are so many terms that people can use in their postings to indicate whether they are under it or not. In this project, the dataset was taken from Kaggle with 116 columns, which will be used to train a machine-learning model for stress detection. For this work, we need to use the text and label columns.
The dataset being used for this assignment includes data from mental health-related Reddit subreddits. It consists of a variety of mental health issues that people have disclosed about their lives. Thankfully, the labels for this dataset are 0 and 1, where 0 denotes no stress, and 1 denotes tension.
54. Password strength checker
To determine the strength of your password, a password strength checker analyzes the combination of your password’s numbers, letters, and special symbols. It uses a labelled dataset of various password combinations of letters and unique symbols to train a machine-learning model. The model learns from data on which letter and symbol combinations are considered solid or weak passwords. Therefore, we need a tagged dataset about various combinations of letters and symbols to create an application to check the strength of passwords. The dataset for this project was discovered from Kaggle that might be used to train a machine learning model to predict a password’s strength.
55. Flipkart reviews sentiment analysis
One of the most well-known Indian businesses is Flipkart. It is an online storefront that goes up against well-known online retailers like Amazon. The task of doing sentiment analysis on customer reviews of products sold on e-commerce platforms is one of the most well-known use cases of data science. The dataset utilized in this sentiment analysis of Flipkart reviews was downloaded from Kaggle.
56. Count objects in an image
One of the tasks of computer vision is to count the items in an image. For this assignment, you can use a variety of computer vision libraries, including OpenCV, TensorFlow, PyTorch, Scikit-image, and cvlib. You must not have heard much about the Python cvlib library. So, this is a straightforward, high-level, and user-friendly Python computer vision library. Python can be used to count the number of objects in an image utilizing the features of this package. Ensure OpenCV and TensorFlow are installed on your systems before using this library.
57. Video games sales prediction
On Kaggle, analyzing data on sales for more than 16,500 video games is a relatively common problem description. You can either use this information to forecast future video game sales or solve this issue to discover a variety of relationships and trends in order between elements affecting video game sales. The dataset utilised in this project includes a list of video games and their sales.
58. Books recommendation system
Online bookstores like Kindle and Goodreads compete with one another on a variety of fronts. Their system for recommending books is one of the best attractions for book lovers. A book suggestion system is made to suggest novels the buyer will find interesting. A book recommendation system aims to anticipate customers’ reading preferences and make appropriate book recommendations. By filtering user reviews, a book recommendation system can consider various factors, including book content and quality. In this project a Python-based machine learning project works a book recommendation system.
59. Satellite imagery analysis
In this project, we’ll analyse satellite imagery of the Indian Sundarbans forest.
The Sundarbans are one of the largest mangrove ecosystems in the Bay of Bengal delta, created by the confluence of the Ganges, Brahmaputra, and Meghna rivers. About 40% of the Sundarbans Forest, which covers an area of 10,000 km2 between Bangladesh and India and is home to various unique and endangered wildlife, is found there. To use Python to analyze satellite imagery, we will only use a tiny portion of the Sundarbans region in this research. We will use a subset of the Sentinel-2 satellite’s Sundarbans satellite data.
The dataset being used has 12 bands, a spectral resolution ranging from 10 to 60 meters, and a size of 954298 pixels.
60. Bitcoin price prediction
Due to its recent price increase, Bitcoin has attracted considerable media and public interest. Because it is traded on numerous cryptocurrency exchanges and is treated as a financial asset, much research has been done on the variables influencing its price and the patterns underlying its volatility.
Several predictive techniques have been investigated and contrasted to predict the price of Bitcoin using machine learning. The project will employ the Facebook Prophet model to predict the price of Bitcoin using machine learning and Python. Facebook has released an open-source additive regression model for time-series forecasting under the Facebook Prophet Library. Although there is a more sophisticated version of the Prophet, such as NeuralProphet, which is based on neural networks, the project uses the more basic version, which uses machine learning techniques to predict the price of Bitcoin.
61. Number plate detection
In all nations, traffic regulation and the identification of car owners have become serious issues. Identifying a driver breaking the law and going too fast on the road might sometimes be challenging.
As a result, it is impossible to apprehend and penalize these individuals because the moving vehicle’s speed may prevent traffic officials from retrieving the vehicle’s license plate. Therefore, a Number Plate Detection System must be developed to address issues of this nature. Systems for reading license plates are widely available today. These systems use many approaches, but it is always challenging because variables like high vehicle speeds, inconsistent license plates, car number languages, and various lighting conditions can significantly impact the overall identification rate. Most systems function within these constraints.
62. Resume screening
Businesses frequently receive thousands of resumes for each job ad, and to weed out qualified applicants, they use specialized screening officers.
Finding the proper talent is a struggle for all firms. If the company is labour-intensive, expanding, and experiencing high attrition rates, this task is made more difficult by a large number of candidates. Resume screening picks out the best candidates from a large pool of applicants. Large organizations typically lack the time necessary to read through each CV; thus, they deploy machine learning algorithms for the Resume Screening duty.
63. YouTube trending videos analysis
The dataset used to analyze the top YouTube videos was compiled over 205 days. It includes information on the most popular videos for each day and more than 40,000 popular videos. The data will be analyzed to gain insight into popular YouTube videos and discover what characteristics are shared by all popular videos. People who desire to boost the popularity of their YouTube videos can also use this knowledge.
64. Hand gesture recognition
The main goal of developing a hand gesture recognition model is to establish a natural interface between a person and a computer to utilise the identified gestures for information transmission or robot control. The gestures might be static (a position or a specific pose) and require less computational complexity, or dynamic (a succession of postures) and require more complexity but are more suited to real-time situations. The project will train a fundamental model that beginners in machine learning may easily understand. This technology has been used in various industries, such as sign language translation, virtual worlds, intelligent monitoring, robot control, and medical systems.
65. Earthquake prediction
Natural calamities, such as earthquakes, can occur anywhere at any moment, yet certain places, such as Japan, are more susceptible than others. Therefore, anticipating an earthquake based on past data such as date, time, latitude, and longitude is not a trend that follows like other things; instead, it occurs organically. As more people utilize technology, there are more seismic monitoring stations, making it possible to anticipate earthquakes using machine learning and other data-driven techniques.
66. Fashion recommendation system
Before making a fashion faux pas, one must consider several factors, including public opinions, fashion regulations, dress codes, and current trends, as although fashion is a personal choice, it is also an art. A recommendation system is computer software that can forecast which things from a vast collection will be preferred in the future. Either the products that all users most frequently choose are used in a recommendation system, or user preferences are used. Creating a recommendation system for the fashion business is particularly difficult because the fashion business is so dynamic.
67. Daily Birth prediction
The Facebook Prophet Model for Daily Births Forecasting Using Machine Learning will be used in the project. The data used in this article is daily female births in California, which is a highly well-known dataset among machine learning practitioners. The Facebook Core Data Science team created the algorithm known as Facebook Prophet. It is utilized in time series forecasting applications. When there is a chance of seasonal effects, it is heavily employed. You will be guided through the project’s implementation of the Facebook Prophet model for machine learning-based daily birth forecasting.
68. Rice plant disease classification and comparative analysis of SVM hyperparameters
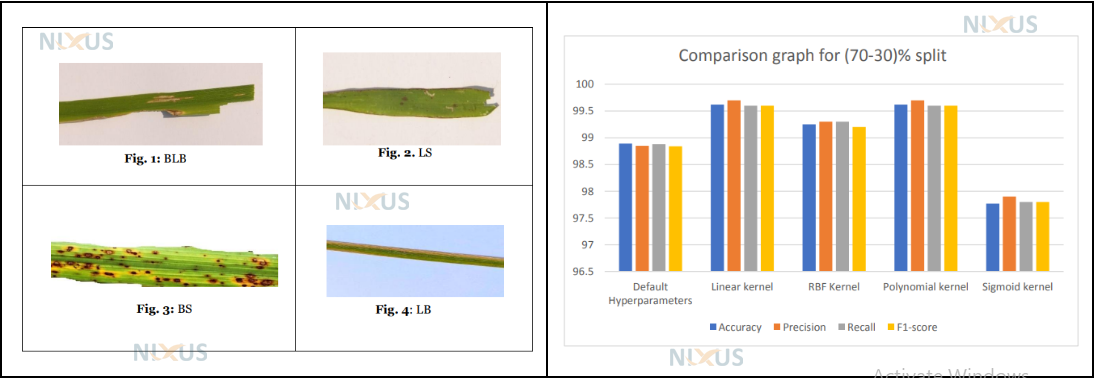
The most severe issues facing farmers today include diseases of the rice plant. Both the crop’s quality and yield are impacted by the illnesses. Traditionally, it takes time to observe or test plant diseases in a lab to diagnose them. A machine learning (ML) approach based on images has been developed by numerous researchers for the detection and categorization of plant diseases. This research introduced an ML-based Support Vector Machine (SVM) kernel approach to identify diseases in rice plants. SVM classification utilises several hyperparameters to evaluate rice plant images early and thoroughly. According to this project’s findings, the SVM model trained using the optimized parameters yielded a maximum accuracy of 0.996.
Conclusion
So, concluding with the wise saying- “Practice makes a man perfect”, which in this context means that to make yourself an expert in Machine Learning, you need to keep experimenting besides the theoretical knowledge. However, it will be beneficial if you first become acquainted with the cutting-edge ML projects described above.