Credit Card Fraud Detection with Python & Machine Learning
With this Machine Learning Project, we will be building a credit card fraud detection system. Credit card fraud has been increasing day by day. There is a need for a system that should be able to tell whether a transaction is a fraud or not fraud.
So, let’s build this system.
Credit Card Fraud Detection System
So, what is this credit card fraud detection system?
It is a type of system or technique used by banks to identify whether the transaction is legit or it is fraudulent transaction. This helps the banks to reject fraud transactions and allow the legit transactions.
There are a number of methods of detecting these frauds. For example – payment cards where you have to enter the details to authorize the transactions which help the banks to identify that the transaction is legit.
In this project, we will be using Machine learning algorithms to detect whether the transaction is legit or fraudulent. We are going to use some machine learning models and see which one works great. Here while detecting the fraud transaction various parameters are kept in mind like the geolocation, time and date, amount, zone, etc.
The Model Architecture
We have to create a model to identify whether a transaction is a fraudulent or legit transaction. So it can be seen as a classification problem. There are a number of classification algorithms that we have in machine learning. In this project, we are going to train our dataset on two models, and then we will compare which one performs better.
For this project, we are going to use Logistic Regression and SVM.
Logistic Regression
It is a popular supervised Machine Learning algorithm. It is often used in classification problem. It often result the probability of occurring of an event. That’s why this model will be great for this project because we are finding the possibility whether a transaction is fraud or legit. Since the outcome is a probability, it often results the answer between 0 and 1. This is the formula for logistic regression.
Logit(pi) = 1/(1+ exp(-pi))
ln(pi/(1-pi)) = Beta_0 + Beta_1*X_1 + … + B_k*K_k
Here the logit(pi) is a dependent variable whereas x is independent. MLE is commonly used in order to estimate the beta parameter, or coefficient, in this model. Multiplication of beta values is performed through multiple iterations to find the most appropriate log-odds fit.
The log-likelihood function is calculated from all of these iterations, and logistic regression attempts to maximize it to determine the best parameter estimate. It is then possible to calculate the conditional probabilities for each observation, log them, and sum them up to calculate the predicted probabilities once the optimal coefficient (or coefficients) have been determined. Probabilities less than or equal to .5 accurately predict 0 for binary classification, while probabilities greater than 0 accurately predict 1.
This is how logistic regression helps in finding the output. After training our model, we are going to test the model on the test dataset.
SVM (Support Vector Machine)
SVM called Support Vector machine is another popular Machine Learning algorithm that is used in classification problems. SVM works in a way that it tries to maximize the hyperplane space between points. These points are nothing but called Support Vectors. That’s why this algorithm is named Support Vector Machines.
The distance between the hyperplane and support vectors is called margins. A hyperplane is a plane that divides the support vectors into two groups that lie on either side of the hyperplane. For a 2D space, this hyperplane is a line. For a 3D space, this hyperplane is a 2D plane.
There are two types of SVM:
- Linear SVM– It is a type of SVM that can divide the dataset into groups just with the help of a line.
- Non-Linear SVM– It is a type of SVM that can not divide the dataset into two groups by using lines. For separating non-linear SVM, we need a circle or hyperbola as a hyperplane.
We can also use the kernel function for solving non-linear SVM. A kernel is a function that will convert the lower dimension problem into a higher dimension function so that it becomes easy to separate them.
This is how SVM works. We are going to use both of them in our model and see which one performs better.
Project Prerequisites
The python modules required for the project are given below.
The required modules for this project are –
- Numpy – pip install numpy
- Pandas – pip install pandas
- Keras – pip install keras
These are the libraries that we will use in our project. I have used Jupyter notebook for the project. You can choose any other notebook as well.
Credit Card Fraud Detection Project
We are providing the credit card dataset that we used for this project. The dataset contains values between 0 and 1. These are the credit card details that are converted into these values to keep the information confidential. Please download the credit card fraud detection machine learning code along with the dataset from the following link: Credit Card Fraud Detection Project
Steps to Implement Credit Card Fraud Detection
1. Here we are importing the Modules required during the project and reading our credit card dataset.
import pandas as pd
df=pd.read_csv('creditcard.csv')
df.head()
import numpy as np
2. Here we are classifying our model as successful and fraud transaction. As the number of successful transaction are much more than fraud transaction, so we are dropping some rows in successful transaction to make a balanced dataset.
success_trans = df[df.Class==0] fraud_trans = df[df.Class==1] success_trans.shape legit = success_trans.sample(n=1000)
3. Here we are combining the dataset again to form a new dataset.
df = pd.concat([legit,fraud_trans],axis = 0) df.shape
4. Here we are dividing the dataset into x and y where x contains the features and y contains the result.
X=df.drop("Class",axis=1)
y=df.Class
5. Here we are splitting the data into training and testing and creating the logistic regression and then training it using the training dataset. After that we are testing it on our test dataset.
from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.75) from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score,confusion_matrix log_class=LogisticRegression() log_class.fit(X_train, y_train) y_pred_lr=log_class.predict(X_test)
6. Here we are creating the confusion matrix corresponding to the predicted value in previous step and y_test. We are using seaborn to create the heapmap. After that, we are printing accuracy.
import seaborn as sns import matplotlib.pyplot as plt cm=confusion_matrix(y_test,y_pred_lr) conf_matrix=pd.DataFrame(data=cm,columns=['Predicted:0','Predicted:1'],index=['Actual:0','Actual:1']) plt.figure(figsize = (8,5)) sns.heatmap(conf_matrix, annot=True,fmt='d',cmap="YlGnBu"); print(accuracy_score(y_test,y_pred_lr))
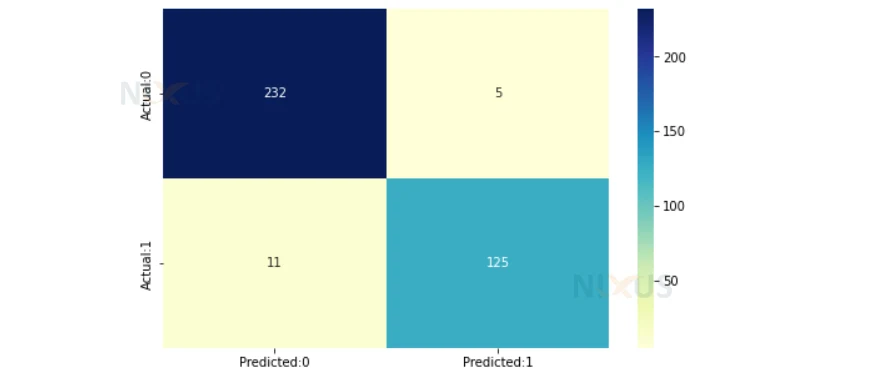
7. Here we are creating the SVM model and then we are training it using the training data and then predicting the result against test data.
from sklearn.pipeline import make_pipeline from sklearn.preprocessing import StandardScaler from sklearn.svm import SVC clf = make_pipeline(StandardScaler(), SVC(gamma='auto')) clf.fit(X_train, y_train) y_pred_svm=clf.predict(X_test)
8. Here we are again creating the confusion matrix for predicted data against y_test.
import seaborn as sns import matplotlib.pyplot as plt cm=confusion_matrix(y_test,y_pred_svm) conf_matrix=pd.DataFrame(data=cm,columns=['Predicted:0','Predicted:1'],index=['Actual:0','Actual:1']) plt.figure(figsize = (8,5)) sns.heatmap(conf_matrix, annot=True,fmt='d',cmap="YlGnBu");
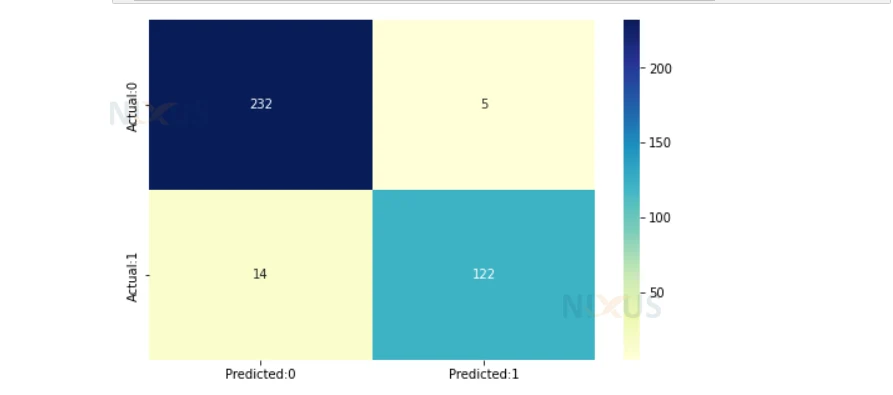
9. Here we are printing the accuracy for svm classifier.
print(accuracy_score(y_test,y_pred_svm))
Summary
In this Machine Learning project, we built a credit card fraud detection system. We built this system using the logistic regression and the SVM classifier also and then we compared the accuracy of both algorithms. We found that logistic regression works better for this project. We hope you have learned something new in this project.