Top Machine Learning Interview Questions with Answers
Interview questions about machine learning and related topics will test your understanding of machine learning theory.
1. List different types of learning/ training models in Machine learning.
Machine learning can be grouped into categories depending on the presence/absence of target variables.
Supervised learning (here, the target is present)
The machine learns using the labeled data. Before making decisions using fresh data, the model is trained on an existing data set. Linear, polynomial, and quadratic regression all use continuous targets for their variables.
The target variable is categorical: Logistic regression, Naive Bayes, KNN, SVM, Decision Tree, Gradient Boosting, ADA boosting, Bagging, Random Forest, etc.
Unsupervised learning (here, the target is absent)
The machine receives no proper guidance and is trained on unlabelled data. Forming clusters automatically deduces patterns and connections in the data. The model learns via observations and concludes the structure of the data.
Principal component Analysis, Factor analysis, Singular Value Decomposition, etc.
Reinforcement learning
The model learns new information using the trial-and-error method. In this method, the agent communicates with the environment to take action and then discovers errors and bonuses of the same action.
2. How do you decide which variables to use while working with a data set?
Following is the list of some of the ways to select an essential variable from a data set:
i. Spot and reject the correlated variables before deciding on a critical variable
ii. We can choose variables based on the p-value of linear regression
iii. Forward, backwards, and stepwise selection
iv. Lasso regression
v. Random forest and plot variable chart.
vi. The top features can be chosen Based on the information gained from the available features.
3. Out of so many machine learning algorithms, how can one decide which algorithm to use for each data set?
The machine learning algorithm that should be utilized only depends on the kind of data in each dataset. Linear regression is used when the data is linear, and the bagging algorithm would do better if the data is non-linear. Decision trees or SVM can be used if the data needs to be analyzed or interpreted for some business purposes. If the dataset contains images, videos, and audio, then a neutral network will be helpful to get solution accuracy.
Therefore, choosing the method for a particular scenario or data set cannot be determined by a single metric. We need to explore the data using EDA (Exploratory Data Analysis) and understand the purpose of using the dataset to develop the best-fit algorithm. Therefore, it is crucial to research all the algorithms thoroughly.
4. List the differences between logistic regression and linear regression.
Following are the main differences between logistic regression and linear regression
Linear Regression:
- It is used to answer the regression problem.
- With the help of independent variables, linear regression is used to predict the continuous dependent variable.
- Linear regression aims to find the best-fit line capable of accurately predicting the output for the continuous dependent variable.
- The least square method is used to evaluate the accuracy
- The output must be a continuous value like age, weight, etc
- The relationship between the dependent and independent variables should be linear.
- There may be collinearity between the independent variables.
Logistic Regression:
- It is used to solve the classification problems
- With the help of independent factors, categorical dependent variables are predicted using logistic regression.
- In Logistic regression, to classify the sample, we first find the S-curve
- To evaluate the accuracy, the maximum likelihood estimation method is used
- The outcome of the logistic regression problem can only fall between 0 and 1.
- The relationship between the dependent and independent variables is not required to be linear.
- There should not be collinearity between the independent variables.
5. What is machine learning, and why do we need it?
Machine learning is a discipline of artificial intelligence (AI) and computer science that uses data and algorithms to simulate how humans learn, gradually increasing the system’s accuracy. Data is the food for all businesses, and the type of data-driven choices you make helps you with the competition and won’t let you fall behind. Unlocking the value of corporate and consumer data and making judgments that keep a business ahead of the competition can be made possible with machine learning.
Machine Learning Use Cases
Advancements in AI for applications like natural language processing (NLP) and computer vision (CV) are helping industries like financial services, healthcare, and automotive accelerate innovation, improve customer experience, and reduce costs.
Artificial intelligence (AI) developments using applications like computer vision and NLP assist sectors like the financial sector, healthcare, and automotive to speed up innovation, enhance customer service, and cut costs. Machine learning is used in all types of industries, including manufacturing, retail, healthcare, financial services, energy, feedstock, and utilities. It is used in cases like
- Manufacturing: Predictive maintenance and condition monitoring
- Retail: Upselling and cross-channel marketing
- Healthcare and life sciences: Disease identification and risk satisfaction
- Travel and hospitality: Dynamic pricing
- Financial services: Risk analytics and regulation
- Energy: Energy demand and supply optimization
6. Can you compare machine learning and artificial intelligence?
The two terms – AI and ML- might be the same, but they’re not, and neither are they interchangeable. AI helps a machine to imitate human behavior, while machine learning allows machines to learn automatically from the existing data without any overt programming. AI can handle all kinds of data: structured, semi-structured, and unstructured, while machine learning only works with structured and semi-structured data. AI is built in a way that helps them perform tasks with human-like efficiency, and machine learning teaches machines to give accurate results with data. AI is more focused on maximizing the chances of success.
On the other hand, ML focuses on the accuracy of the results and patterns. For example, applications like Siri, humanoid robots, AI-powered games, and customer support chatbots like ChatGPT use AI. At the same time, machine learning is employed in products such as Netflix program recommendations, Facebook tagging, and Google search algorithms.
7. Do we have to know programming languages to learn ML?
Yes, a little coding is a must if you’re pursuing a career in machine learning. Machine learning is implemented through coding, and if you understand programming, like how to implement that code, you’ll know how the algorithm works and be able to monitor and optimize those algorithms.
The most used programming languages are C++, Java, and Python, but you need basic knowledge of others for specific algorithms. When diving into machine learning, languages like R, Lisp, and Prolog become essential. You don’t need to know HTML or CSS; instead, start with the more relevant languages like Python, which are considered relatively easy to learn because of features like their use of English words instead of punctuation.
8. Can you explain regression and classification in machine learning?
Algorithms categorize the observations, findings, and events into groups. For example, when you classify specific mail as spam in your email, whenever an email is delivered to your address, the email filter will either classify it as “spam” or “not spam.” This is just a simple way to explain, but in the actual scenario, the predictive powers of such models have a massive impact on how a decision will be made and what strategy will be formed.
Both regression and classification are used to oversee machine-learning problems, which are used to predict the value or category of the result.
When discussing classification analysis, we must remember that the dependent attribute is categorical. A classification task learns how to categorize a class label using examples from the problem domain. As I mentioned above, a typical example of classification is a spam filter in your mail.
In regression analysis, the dependent attribute is numerical. It is used when the output variable is accurate, such as a continuous value like salary or age.
The main difference between the two is that one predicts a label (in case of classification, like “spam” or “not spam”), and the other predicts a quantity (in case of regression).
9. How do you import different algorithms in ML?
The following code snippet represents different library packages necessary to import ML algorithms.
from sklearn.neighbors import KNeighborsClassifier from sklearn.naive_bayes import GaussianNB from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.neural_network import MLPClassifier
10. What do you understand by the term flask?
Flask is a web framework that provides us with the tools, libraries, and technologies required to design a web application. The said web application can be anything like web pages, a blog, a wiki, or anything as significant as a web-based calendar application or a commercial website. A framework is a group of reusable code or extensions for everyday activities that should make work easier, scalable, efficient, and maintainable web applications for developers.
Flask and HTML are interrelated. HTML connects the user whenever the user sends information on the Internet or searches in the search bar. The Flask framework looks for templates and HTML files in a folder. Phyton code is carried out on the template before sending it over, introducing variables, codes, etc.
11. What do you mean by model selection?
Model selection is choosing a single machine-learning model from a group of candidate models for a training dataset. It can be applied to different models, such as logistic regression, SVM, KNN, etc., and to models with different model hyperparameters but with the same configuration, like different kernels in an SVM. In simple words, model selection is the phenomenon of choosing a model out of others that addresses the problem.
12. Distinguish between deep learning and machine learning.
Following are the five most important differences between the subsets as mentioned earlier of artificial intelligence:
I. Human Intervention: Machine learning must deliver results through continuous human intervention. Although it is more difficult to set up, deep learning requires less intervention once it functions.
II. Hardware: Machine learning programs are less complex and can often run on conventional computers, unlike deep learning, which requires complex and powerful resources and hardware. The demand for high power usage has led to increased graphical processing unit (GPU) use. GPUs are advantageous due to their high bandwidth memory and capacity to mask memory transfer latency (delays) due to thread parallelism (the ability for multiple operations to run effectively simultaneously).
III. Time: Machine learning systems can be set up and operated quickly, but their effectiveness may be constrained. On the other hand, deep learning systems take relatively more time to set up but generate results rapidly (but the quality likely depends upon the amount of data available).
IV. Approach: Machine learning uses traditional algorithms like linear regression, which requires structured data. In contrast, deep learning applies neutral networks and is built to deal with large volumes of unstructured data.
V. Applications: Machine learning is used everywhere, including your email inbox, bank, and doctor’s office. Since deep learning technology is related to more complex and autonomous programs, it is used in robots that perform advanced surgery or self-driving cars.
13. What do testing, training, and validation sets mean?
The Training Set: This data set is responsible for training and making the model learn the hidden features/patterns in the data. The same training data is fed to the neural network architecture repeatedly in each epoch, and this way, the model continues to learn the features of the data. The training set should have a diversified set of inputs to train the model in all scenarios that can predict any unseen data sample that may appear in the future.
The Validation Set: It is separate from the training set used to validate our model’s performance during training. The validation process provides information that aids the model’s hyperparameters and configurations. After every epoch, the model is evaluated on the validation set while being trained on the training set.
The key objective of dividing the dataset into a validation set is to prevent our model from overfitting, which occurs when the model gets exceptionally good at identifying samples in the training set but struggles to generalize to new data and make accurate classifications.
The Test Set: After completing the training, a separate data set is used to test the model. This provides an unbiased final model performance metric for accuracy, precision, etc. In other words, it answers the question, “How well does the model perform?”
14. Which is more essential, model accuracy or model performance?
Questions like these are asked to check your depth of knowledge about machine learning models, and they always test the details of your understanding. We have models with high accuracy rates but can perform poorly in predictive power, but how?
Here, you must understand that model accuracy is a subdivision of model performance and can sometimes be ambiguous. For instance, say we have a large data set of weather predictions and want to find out whether it will rain tomorrow. An accurate model will give us results stating that it will not rain, but it will rain the next day. This derails the effectiveness of the predictive model as it is designed to predict the weather that failed to do so. Such questions will help you reflect on the depth of your understanding and that you have not just crammed everything there is to know about model accuracy.
15. If you are given an imbalanced set of data, how would you handle it?
An imbalanced dataset is when you have no balance in the data, like, say, you have asked a set of questions, and 80% is in one class and 20% is in another. This can affect the accuracy as 80% can be skewed, and you will have no predictive power over the other class. You have to try to remedy the imbalance as it can cause damage to your work, and you need to learn to balance it. Here are a few methods:
i. By collecting more data- this method evens out the imbalance present in a dataset
ii. You can resample the dataset
iii. Use an alternate algorithm for the dataset.
16. How do you know your data is overfitting, and how do you prevent it?
When your model does well on the training data but not on the evaluation data, you know that your model is overfitting your data. This happens when the model retains the already-seen data and cannot generalize it to unseen data.
You can prevent this by following these methods:
i. The simpler the model, the fewer chances of data overfitting. To minimize variance, use fewer variables and parameters. This way, you can undo some noise in the training data.
ii. Cross-validation techniques should be used, such as K-fold cross-validation, Hold-out cross-validation, and stratified K-fold cross-validation.
iii. Regularization techniques should be used to hold the model parameters accountable if overfitting arises.
17. Which evaluation practice should be used to test the success of a machine learning model?
It is important to note that you must show that you understand how a model is measured and the correct performance practices in the right situation. You will start by breaking the dataset into test and training sets. You can use cross-validation techniques to further segment the dataset into composite tests and training sets within the data. Then, you will apply alternative performance metrics like measuring accuracy and the confusion matrix.
18. What do you understand about the “kernel trick” and its uses?
In simple terms, the kernel trick helps transform any data from its original dimension to a higher dimension. It involves a kernel function that can enable higher-dimension spaces without explicitly calculating the coordinates of points of the same dimension. Instead, the functions calculate the inner products between the images of all data pairs in a feature space. This enables them to calculate the coordinates of higher dimensions, a valuable feature computationally less expensive than explicitly calculating those coordinates. Using this method, one can efficiently run algorithms in a high-dimensional environment with lower-dimensional data.
19. What is the difference between KNN and k-means clustering?
The simple difference between the two is that KNN (K-nearest neighbors) is a supervised classification algorithm, and k-means clustering is unsupervised. For KNN to work, the data must be labelled, and the unlabeled ones must be into (thus the nearest neighbour part).
K-means clustering needs a collection of unlabeled points and a threshold; the algorithm will take hold of unlabeled points and slowly learn how to cluster them into groups by calculating the mean of the distance between different points.
20. Which algorithm will you consider your favourite and why?
Such questions are asked to test your understanding of the technical concepts and how easily you can apply them. Here, I will talk about the “Decision Tree” algorithm as I find it easy to explain. You can always list your favorite, but make sure that you have a complete understanding of the said algorithm.
Decision Trees: As the name suggests, the algorithm uses decision trees to make the prognosis. The algorithm functions by breaking the data into sub-divisions based on the most essential characteristics of each tree node. Overfitting can be avoided by defining the tree’s maximum depth or minimizing the sample size to allow another division of the final tree after completion.
Advantages of the algorithm:
i. Easy to understand.
ii. The algorithm performs the selection function.
iii. Minimal data preparation is required
21. What is feature selection? Explain.
Feature selection is the automatic or manual selection of data features (such as columns in tabular data) that are most important to the predictive modeling problem. A subset of features is chosen with attention to the accuracy, relevance, and usefulness of the output. The predictive model’s accuracy is improved by identifying the irrelevant attributes and removing them from the data. You can always control the complexity or simplicity of the model by controlling the data.
For example, simpler models use fewer datasets and vice versa. Feature selection gives rise to a vigorous predictive model by reducing overfitting, improving accuracy, and reducing training time.
22. How do you use StandardScaler and MinMaxScaler Transforms?
Answer: Before modeling, normalization and standardization are the two most widely used methods that scale the numerical input data.
ML models that employ input’s weighted sum, such as linear regression, and methods using distance measures, such as KNN, operate more effectively when the numerical variables are scaled to a joint range. You may normalize your dataset with the help of the scikit-learn object MinMaxScaler.
The sklearn (scikit-learn) library and the MinMaxScaler object are used for normalisation, whereas the StandardScaler object of the sklearn library standardises the data.
Here’s an example of implementing each feature scaling technique using Python.
from numpy import asarray from sklearn.preprocessing import MinMaxScaler nixus_input = asarray([[94, 0.002], [2, 0.01], [30, 0.002], [76, 0.03], [2, 0.01]]) print(nixus_input) nixus_scaler= MinMaxScaler() nixus_scaled = nixus_scaler.fit_transform(nixus_input) print(nixus_scaled)
Output
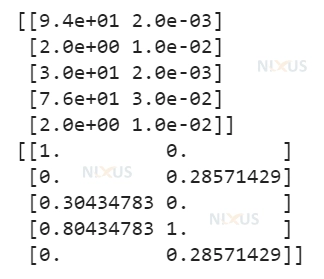
from numpy import asarray from sklearn.preprocessing import StandardScaler nixus_input = asarray([[94, 0.002], [2, 0.01], [30, 0.002], [76, 0.03], [2, 0.01]]) print(nixus_input) nixus_scaler = StandardScaler() nixus_scaled = nixus_scaler.fit_transform(nixus_input) print(nixus_scaled)
Output
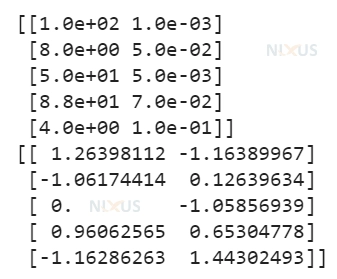
23. Why is SVM called a maximum margin classifier?
SVM (Support Vector Machine) is a supervised machine learning algorithm for classification and regression. It divides data into two parts, and the output is a map of the sorted data with the margins between the two data points as far apart as possible. Now, SVM is called a maximum margin classifier because it positions the decision border in a binary classification dataset to maximise the distance between the two clusters. By forming the most extensive margins, SVM avoids overfitting.
24. Can you give the fundamental differences between precision and recall?
Both precision and recall measure the relevancy of outcomes and are model evaluation metrics. They are utilized in pattern recognition, binary classification, and information retrieval.
i. Precision, as the name suggests, is the percentage of the relevant outcomes. On the other hand, recalls mean the percentage of the total relevant outcomes retrieved over the total number of relevant instances. For instance, in a search engine result for a “search,” precision is the number of retrieved content similar to the search. At the same time, recall is the number of similar documents successfully retrieved.
ii. Precision is the answer to queries like “How many search results were correct related to the search?”
And recall answers to queries like “How many search results were identified as correct results of the search?”.
iii. Precision and recall are contradictory; if you increase one, the other will decrease, and vice versa.
iv. High precision means that an algorithm returned the most relevant results, but high precision denotes that an algorithm provided significantly more relevant results than irrelevant ones.
v. Precision evaluates the quality of the model’s results, while recall evaluates the quantity.
25. Explain how one can choose an algorithm for a classification problem.
We cannot say that there is a step-by-step universal known procedure to follow because several factors go into the machine learning algorithm. The factors are the accuracy level needed and the training set’s size.
Following are the sample steps:
i. The first step would be to describe the problem:
Given that this is a classification problem, the model’s output is a class
ii. Classify the available algorithms into linear and nonlinear
- Logistic regression
- Linear discriminant analysis
- K-Nearest neighbors
- Classification and regression trees.
- Naïve Bayes
- Support vector machines
iii. The next step would be the implementation of those mentioned above.
We need to create a machine learning pipeline that measures the performance of each algorithm on the dataset using a set of assessment tests or chosen metrics. The best ones will be selected. Depending on the results, the pipeline may be run only once or repeatedly as new data is added.
iv. You can improve the results by using optimization methods.
If time is not a constraint, each algorithm would be modified to optimize performance using cross-validation (like k-fold) and hyperparameter tuning or Ensembling (bagging, boosting, etc.). Otherwise, choose the hyperparameters manually.
26. Can you explain what a genetic algorithm is?
Genetic algorithms are very reliable and can be used for various optimization problems. Unlike other AI algorithms, these algorithms do not deviate easily in the presence of noise. We can use them in the search for ample or multimodal space.
Genetic Algorithms are very much like the evolution of biological beings. Charles Darwin’s theory of evolution is based on the principle of “survival of the fittest.” Genetic Algorithm search is designed to work on the same principle. When attempting to tackle optimization issues, GAs perform random searches to solve the problem. They then apply methods that focus their search on optimization in the new search space using previous historical information.
27. How do mean, median and mode work for some numerical data in ML?
The following code snippets help you understand how to calculate some data’s mean(average), median, and mode.
1. Mean
nixus_num = [34, 63, 55, 27, 48]
nixus_len = len(nixus_num)
nixus_total = sum(nixus_num)
mean = nixus_total/ nixus_len
print("The mean of all the numbers is (", nixus_num, ") is", str(mean))
Output
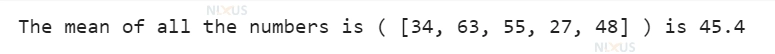
2. Median
nixus_num = [34, 63, 55, 27, 48]
nixus_len = len(nixus_num)
nixus_num.sort()
if nixus_len % 2 == 0:
nixus_median1 = nixus_num[nixus_num//2]
nixus_median2 = nixus_num[nixus_len//2 - 1]
nixus_median = (nixus_median1 + nixus_median2)/2
else:
nixus_median = nixus_num[nixus_len//2]
print("The median of all the numbers (", nixus_num, ") is", str(nixus_median))
Output
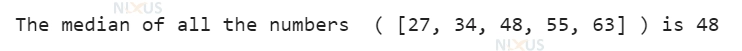
3. Mode
from collections import Counter
nixus_num = [34, 35, 35, 33, 40]
nixus_len = len(nixus_num)
nixus_value = Counter(nixus_num)
nixus_findMode = dict(nixus_value)
nixus_mode = [i for i, v in nixus_findMode.items() if v == max(list(nixus_value.values()))]
if len(nixus_mode) == nixus_len:
nixus_findMode = "The given numbers' group does not have any mode"
else:
nixus_findMode = "The mode of a number is / are: " + ', '.join(map(str, nixus_mode))
print(nixus_findMode)
Output
![]()
Conclusion:
I hope you enjoyed learning these questions. Remember to practice your communication skills and be ready to ask questions to show interest and curiosity. With these tips, you can be well-prepared for your machine learning interview and take a step closer to achieving your career goals. Good luck for your interview!!