Classification vs Regression in Machine Learning
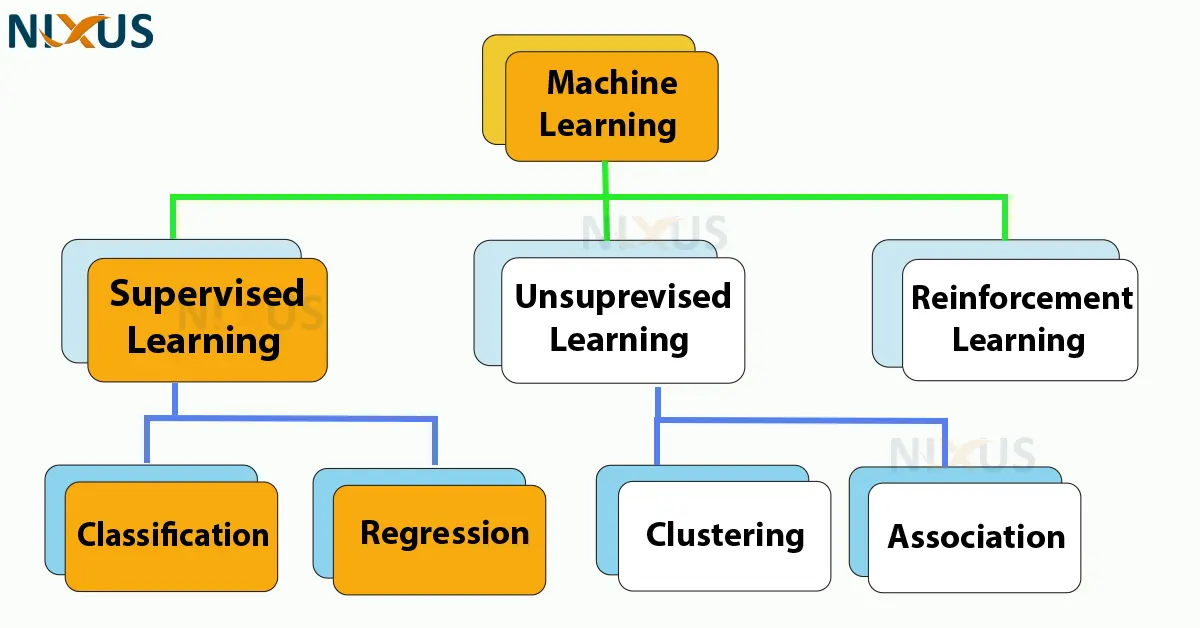
In order for a computer to learn and make predictions, detect patterns, or classify data, a lot of data must be presented to it. This process is known as machine learning. The three types of machine learning are supervised learning, unsupervised learning, and reinforcement learning.
In machine learning, predictions based on labeled datasets are done using either regression or classification algorithms. Regression and classification where on one hand belongs to the same category of machine learning techniques (i.e supervised learning) but on the other hand both these terms differ with respect to the types of problems these are used in.
Regression is used for problems with continuous forms of data such as salary, marks, age, etc. while classification algorithms are used for data with categories or discrete values such as Men or Women, Yes or No, Good or Bad, etc.
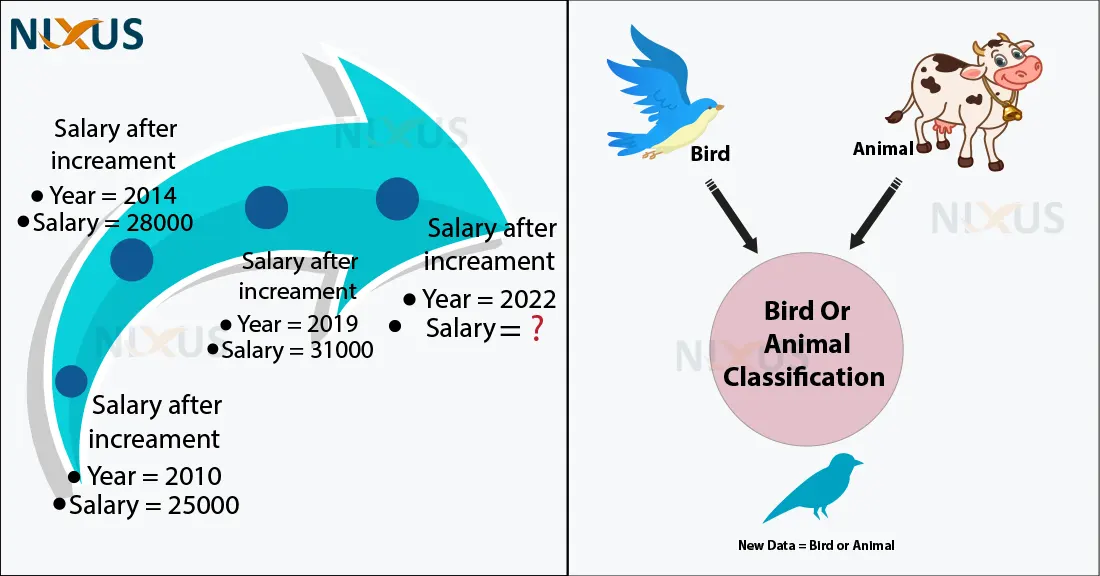
The above figures represents two problems where first problem needs a value which could be attained using the previous data which is in continuous form whereas the second figure shows the classification problem where the model is already trained with two categories (i.e Bird or Animal) and whenever there is any new entry, the model classify it accordingly.
Regression in Machine Learning
Regression algorithms are used to find the correlations between the data i.e dependent variables and independent variables. The input for a process being evaluated is independent variables(x) (also known as Features). The dependent variables(y) are the process’s output.
Regression is used as a predictive model to evaluate the outcome of continuous order. In regression, the major task is to map the input value (x) to the continuous output variable (y).
The aim is to find the best fit line in regression so that the output may be predicted more precisely. Regression techniques are further divided into three categories. Let’s discuss each of these categories with examples.
1. Simple Linear Regression:
A mapping function is used in simple linear regression to model the linear relationship between an independent variable and a dependent variable that must be predicted. Consider, for illustration, that a locality’s housing costs are only influenced by its geography. So, basing the trained model on historical data, one may forecast housing costs given the area of any new region.
2. Multiple Linear Regression:
Regression of this kind involves establishing a connection between a number of independent variables and a dependent variable. For instance, a restaurant’s evaluations are influenced by the caliber of the food along with the ambience, site, and services. Therefore, in this situation, several independent variables influence the dependent parameter linearly (restaurant’s rating).
3. Polynomial Regression:
The non-linear correlation between the independent and dependent variables is mapped by this algorithm. The mapping has a nonlinear equation since it uses several powers of an independent variable. This kind of algorithm, for instance, can be used to forecast the Covid-19 cases. Polynomial regression can map the non-linearity and forecast since the growth or reduction in cases is not linearly connected to the number of persons wearing masks.
Another example would be the effect of temperature rise on the chemical synthesis process. Chemical scientists frequently make use of this method to establish the ideal temperature at which chemical synthesis can occur.
Regression Example
To predict the age of a person based on his features (such as hair, face, eyes, etc), regression algorithms are used. In age prediction, the past data is provided to the model for training, and after that, the age of prediction can be done easily for any future purpose.

In the example above, the regression problem will execute for the problem- “What would be the age of the person based on their look?”. For this, a scale has been shown. The scale contains values starting from 1 year old up to 95+ years old age of a person. Once a model has been trained with the data that explains the features of people of particular age, it would predict the age for the future entries.
Types of Regression algorithms
- Linear regression
- Polynomial regression
- Support Vector regression
- Random Forest regression
- Decision Tree regression
Use cases of Regression
- Age prediction
- Weather prediction
- Market trend prediction, etc.
Classification in Machine Learning
Classification algorithms are those which help to predict the output as classes/categories taking labeled data as input. It is a form of supervised learning algorithm that, after being trained using training data, predicts the class of data. Labeled data is used to train the model and after training, new data is classified into classes/categories accordingly. In classification, the task is to map the input value(x) to the discrete output variable (y).
A continuous number is frequently predicted by classification models as the possibility that a given example will belong to each output class. The possibilities can be considered as a measure of how likely or certain a given example belongs to a particular class. The class label with the highest probability can be chosen to represent a predicted probability as a class value.
The aim is to find the classification decision boundary that further allows categorisation of the dataset into different groups.
The three main categories of classification issues are binary, multi-class, and multi-label. Let’s elaborate each term with examples.
1. Binary Classification:
There are two possible categories for this classification issue. In order to classify a person’s age as young or old, for instance, let’s assign label 0 for young and label 1 for old, which will transform the output probabilities to either of these labels and turn the problem into a binary classification problem.
2. Multi-Class Classification:
In this case, a class may be classified from more than two classes. Let’s consider an example with historical data for a mall that classifies each person entering the mall into one of three categories: children, adults, or elders. Then, using this data a model can be trained, and each entry into the mall in future can be predicted, which may fall into any of the aforementioned categories.
This model could help the mall authorities to get a greater idea about the age groups that visit more frequently and in large numbers. Consequently, they could make the necessary improvements to their atmosphere to make it more appealing to people of different age groups. Multi-class classification can be shown in this case.
3. Multi-Label Classification:
In multi-label classification, various labels serve as the results of a specific prediction. A given input may belong to more than one label when creating predictions. For instance, when anticipating a certain movie genre, it may fall under the headings of thriller, drama, action, comedy, or all of these at once. This means that a multi-label classification problem arises when the same input can be classified into one, two, or more categories.
Example of classification in ML
To classify a person as either young or old based on his features (such as hair, face, eyes, etc), classification algorithms are used. For this prediction, the past data is provided to the model for training, and after that, the categorization of a person can be done easily for the future.
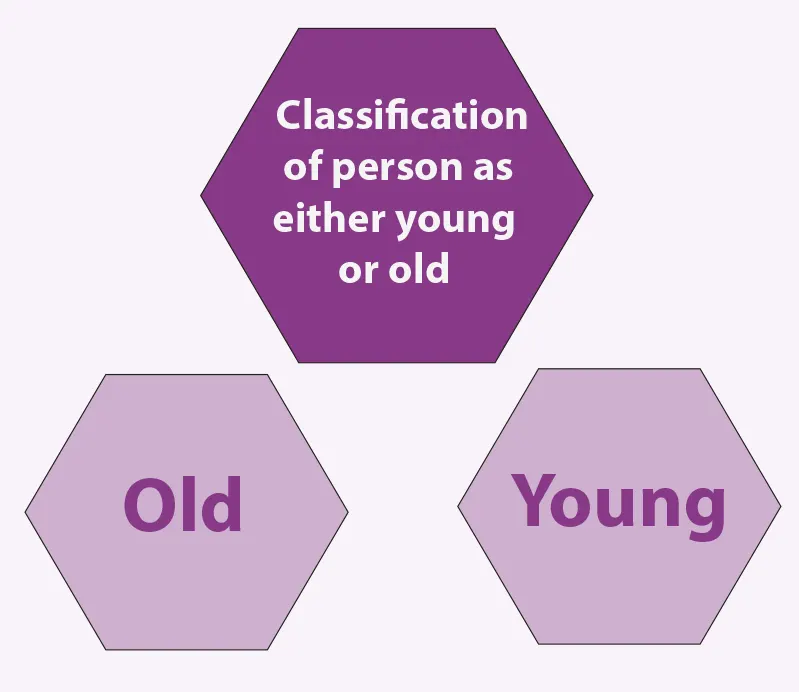
In the above example, the classification problem will execute for the question- “Is this person Young or Old?”. two categories of humans have been given- (i) Young and (ii) Old. A model trained on the basis of features of different age groups will do the categorization of every new entry as either the person is old or the person is young.
Types of classification algorithms
- Logistic Regression
- Support Vector Machine
- K-Nearest Neighbours
- Kernel SVM
- Naive Bayes
- Decision Tree classification
- Random Forest classification
Use cases of Classification
- Email spam detection
- Disease Detection
- Speech Recognition
- Face recognition, etc.
Difference Between Regression vs classification in Machine Learning
| Regression | Classification |
| The task of predicting a continuous quantity is known as regression. | The classification process involves anticipating a discrete class label. |
| The task is to map the input value (x) to the continuous output variable (y). | The task is to map the input value(x) to the discrete output variable (y). |
| A regression model can predict a discrete value, but only in the form of an integer quantity. | A classification model can predict a continuous value, but it is in the form of a probability for a class label. |
| The output variable in regression must be of continuous value. | The output variable in Classification must be discrete. |
| Regression algorithms can be used to resolve other regression issues, such as weather prediction, age prediction, market movements, and more. | Some uses of classification algorithms include speech recognition, email spam detection, and plant disease categorization. |
| Three categories of regression are- simple linear regression, multiple linear regression, and polynomial regression. | Three categories of classification involve- binary classification, multi-class classification, and multi-label classification. |
Conclusion:
So, we went over some of the concepts underlying Regression and Classification. We have also discussed the major differences of these algorithms. We’ve seen how these two algorithms are used in real-world situations.