Convolutional Neural Network – CNN
A neural network type called a convolutional neural network, or CNN or ConvNet, is particularly proficient at processing input with a grid-like architecture, like an image. A binary number of visual input is a digitized picture. It comprises a grid-like arrangement of pixels, each having a pixel value to indicate how intense and what color it should be.
CNN Architecture:
A generic CNN unit has four components or layers:
- Convolutional layer
- Rectified Linear Unit layer
- Pooling layer
- Fully Connected layer
These are explained below in detail:
1. Convolutional layer:
The source picture’s properties are initially extracted using the convolution layer. The convolutional layer preserves the link among pixels by utilizing a tiny area of input data to learn picture attributes. This analytical procedure requires two sources: a digital image and a kernel or any other filter.
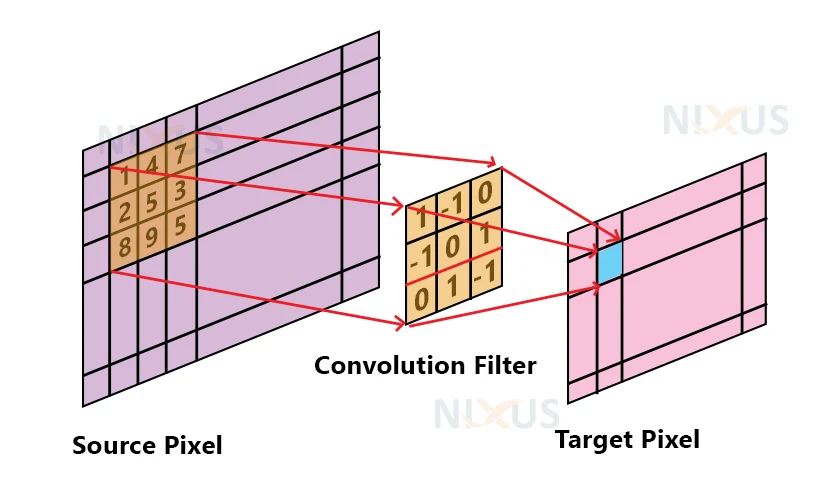
The picture matrix has a height, width, and depth.
Any filter has a size of fh x fw x d.
We get outputs in dimension (h-fh+1)(w-fw+1)1.
2. RelU layer:
Rectified Linear Unit (ReLU) transformation methods only turn on a node if the input value exceeds a specific threshold. Whenever the input climbs beyond a specified limit, the output changes from zero, whereas the data is less than zero. The input and the predictor variables have a linear relation.
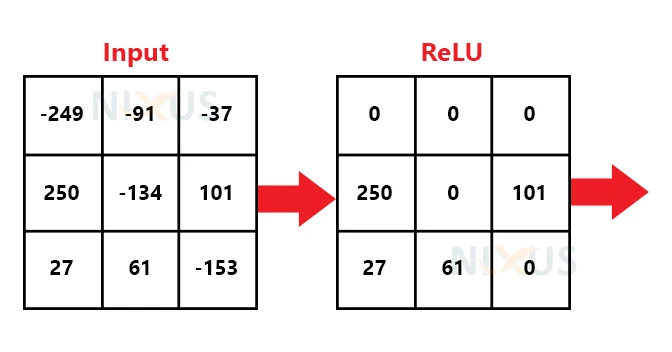
Every value below zero in the filtered photos is eliminated and replaced with 0 at this level. We do this to prevent the numbers from summing up to zero.
3. Pooling layer
The pooling layer is a crucial component of any picture pre-processing. The pooling layer lowers the parameter value when the image is too big. Pooling entails “downscaling” the picture produced by earlier layers. It is comparable to shrinking a picture to lessen its density.
Downsampling and subsampling are other names for spatial pooling. It lessens the dimensionality of the feature while maintaining crucial data.
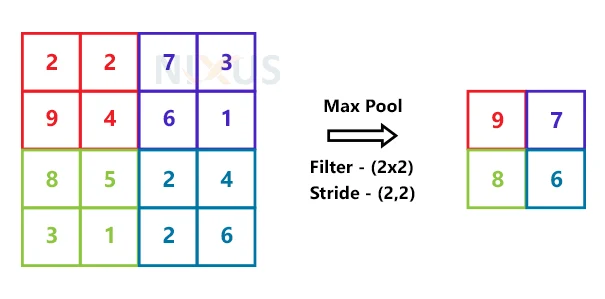
To do this, we put the following 4 stages into practice:
- Choose the window size (usually 2 or 3).
- Choose a stride (usually 2).
- Observe your filtered photographs when you move your window.
- Take the highest value available from each window.
There are many ways to carry this out. Some of them are:
a. Sum Pooling:
The sub-region is configured precisely the same for sum or average pooling as it is for max pooling. However, you can use the sum or average method instead of the max method.
b. Max Pooling:
A sample-based discretization technique is max pooling. Its primary goal is to reduce input dimensions and form assumptions about the characteristics of the chosen sub-region.
You can accomplish max-pooling by using a max filter on non-overlapping subdomains of the original image.
c. Average Pooling:
By splitting the inputs into square pooling zones and calculating the mean results of every area, you can perform mean pooling down-scaling.
4. Fully connected layer:
The output from other levels will lower into the vector at the fully connected level (also known as the dense layer). The output will create any required number of groups in the network. A completely linked layer transforms the map matrix into a vector in the picture above, such as x1, x2, x3, etc. To categorize the outputs as a vehicle, vegetable, carrot, etc, it will mix characteristics to form any models and then use activation functions such as softmax or sigmoid.
Working of Convolutional Neural Network
Various levels of artificial neurons make up convolutional neural networks. Artificial neurons are computational models that compute the weight matrix of multiple inputs and output an activation level similar to their natural equivalents. Every level creates many activation functions transferred onto another level when you enter a photograph into a ConvNet. There are four layers in CNN.
The first level generally extracts basic characteristics such as vertical or horizontal lines. Then, this data is communicated to the next level, which is responsible for detecting more complicated features like corners and combinational lines. As we go further into the network, it can progressively recognize more complex elements like items, persons, etc.
CNN Significance:
1. It saves memory
The multiple levels of a CNN are generally convolutional, pooling, and connected directly. The foundational component of the CNN is the convolution layer. It handles the majority of the computational burden on the system.
2. Local variables are independent:
This layer creates a dot product between two matrices. One is the kernel—a collection of trainable parameter values and the other is the constrained area of the perceptron. The kernel may be smaller in space but is deeper than a picture. It indicates that the kernel height and width will be physically tiny if the image consists of three (RGB) channels, but the depths will go up to all three color channels.
3. It has equivariance:
Equivariance is a characteristic of CNNs that you can see as a particular type of parameter exchange. A function is theoretically said to be equivariant if its output changes with change in the input. You may express it numerically as f(g(x)) = g(f(x)).
Convolution layers are equivalent to many data processing procedures, making it easier to determine how a specific change in the input would impact the output. As a result, it makes it easier to see any significant changes in the output and maintain the model’s dependability.
Applications of Convolutional Neural Network:
1. Object recognition:
Thanks to CNN, we now have advanced algorithms like R-CNN, Fast R-CNN, and Faster R-CNN that serve as the main pipelines for many object recognition algorithms used in driverless cars, image identification, and other applications.
2. Caption generation:
Recurrent neural networks are combined with CNNs to create descriptions for photographs and videos. Examples include movement detection and providing descriptions of films and pictures for blind people. Youtube uses this to make its videos accessible.
3. Segmentation:
To include rich data into an image segmentation algorithm, a team of academics from Hong Kong created a CNN-based Deep Parsing Network in 2015. Additionally, UC Berkeley scientists developed fully convolutional networks that outperformed advanced semantic segmentation.
Conclusion
Starting with an input picture, we will use various image features, also known as filters, to produce feature maps that make up a convolution layer. Then, to eliminate any linearity or enhance non-linearity in our photos, we will apply the ReLU, or Rectified Linear Unit, over that level. Finally, to ensure that our pictures maintain spatial regularization, we will attach a Pooling layer to our Convolutional layer, creating a Pooled feature map from each individual feature map. Additionally, it aids in minimizing the length of our photos and prevents any sort of information overfitting.