Decision Tree Algorithm in Machine Learning
A standard data mining method is decision tree learning, a supervised machine learning technique. A decision tree is similar to a diagram that people use to illustrate a statistical likelihood or determine the course of an event, an action, or an outcome. The idea is more straightforward to comprehend with the help of a decision tree illustration.
You continually weigh three key concepts for decision-making in daily life – advantages, expenses, and probability, whether it is selecting the kind of shoes to purchase or choosing the best insurance for your family. We can formalise this thought process into an algorithm known as a “decision tree,” which is particularly helpful for individuals working in machine learning.
Decision Tree Algorithm
With decision trees, the data is continuously divided based on a particular parameter. This is a type of supervised machine learning where you describe the input and the corresponding output in the training data. Two things—decision nodes and leaves—can explain the structure of the tree. The leaves represent decisions or outputs. Furthermore, the data is divided at the decision nodes.
Similar to flowcharts, decision trees begin with a root node, which contains a specific data question that connects to branches with possible responses. The internal nodes at the end of the branches then have further questions and provide additional results. This continues up until the data reaches a terminal node and comes to an end.
Decision trees are beneficial for machine learning and data science because they break down complex data into more manageable chunks. They have been a great help in problems dealing with classification and regression, and thus work out as a good predictor and analyser.
The following steps can help explain the process by which the decision tree works.
1. The most suitable attribute out of the whole dataset is selected with the help of Attribute Selection Measures (ASM) to split or divide the records.
2. After selecting that attribute, act as a decision node, and the whole dataset D is split into smaller subsets.
3. At this point, building up the tree starts with a continuous repetition of steps 1 and 2 recursively for every single child node. Here, this process will be repeated until there are no attributes or instances left.
Suppose our dataset contains a large number of attributes, and selecting an attribute at random as our root node could lead to a complex process, which directly affects the accuracy of our model.
Therefore, adequate measures were needed to address such issues, which led researchers to develop the following formulae that they suggested be considered when calculating the suitable attribute.
1. Entropy
Structure of the Decision Tree Algorithm
As you begin your decision tree adventure, it will be helpful to be familiar with the following phrases, which are used frequently in the field:
- Decision nodes: Symbolizing a decision (usually represented by a square).
- Chance nodes: Symbolizing uncertainty or probability (usually shown by a circle)
- End nodes: Symbolizing a result (usually represented by a triangle)
‘Branches’ are the connections that exist between the nodes mentioned above. Trees of varying complexity can be made by repeatedly combining nodes and branches in a variety of ways.
The following are some more terms that help to understand the structure of decision trees:
- Root node: The root node is the uppermost node in the decision tree, representing the complete message or choice.
- Internal node: Node in a decision tree known as an internal (or decision) node that branches off to more than one variable from the preceding node.
- Leaf node: The final and furthest node in a decision tree is known as the leaf node, also referred to as the external node or terminal node, because it has no children.
- Splitting: separating a node into more than one node is known as splitting. It’s the section where the decision splits or branches into other variables.
- Pruning: It is the reverse of splitting, which is the act of walking through the tree and removing all except the most crucial nodes or outcomes.
Example of a Decision tree
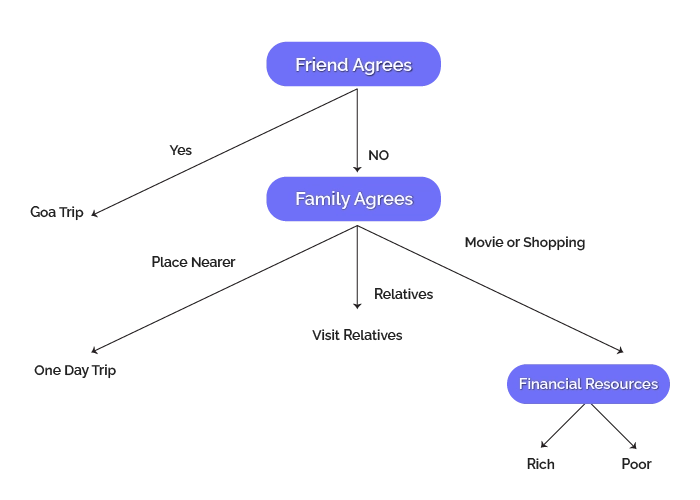
1. Scheduling trip:
Let’s begin by creating a simple decision tree for scheduling the Goa trip. As you can see, we could go on the journey if a friend agrees to come. If not, the family would be a factor. When the family is not ready to allow you to go this far, it’s best to visit somewhere other than for a one-day trip; when the family suggests visiting relatives, we can go out there. If the family allows you to go and watch movies with friends, we can choose to go shopping or to the film, depending on our financial resources.
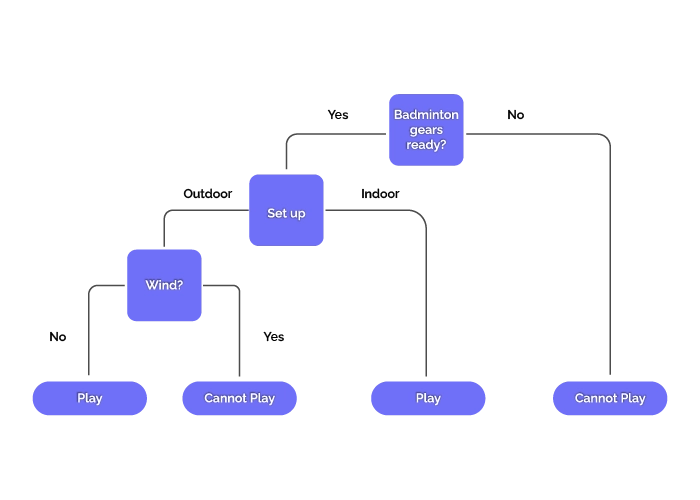
2. Whether or not to play badminton:
Imagine trying to decide whether you can play badminton, taking into account various factors. You can use the decision tree shown below to determine which option is selected.
Advantages of Decision Tree
- Extremely useful for interpreting highly visual data.
- Good at managing data in both numeric and non-numeric forms.
- Simple rules like “yes, no, if, then, else,” etc.
- Minimal setup or data cleansing is required before use.
- An excellent method for comparing the most likely, worst-case, and most important possibilities.
- It is simple to integrate with other methods of decision-making.
Disadvantages of a Decision Tree
- Overfitting can take place.
- Decision trees are susceptible to even minute modifications in the data.
- They may have biases in favor of particular outcomes.
- It can be challenging to interpret big decision trees.
- With certain types of data, they may not perform as expected.
Applications of the Decision Tree
There are various domains where the decision tree is being used and has been successful in providing the required outcomes. Some of the domains are listed below.
- Business field
- Stock market analysis
- Fault detection
- Banking sector
- Agriculture domain
- Customer management system
- Medical and healthcare management
- Finance sector
Conclusion
Decision trees are utilised across various industries to address a range of issues. They are used in a variety of fields due to their flexibility. They have widespread practical applications in multiple fields, including medicine, banking, and agriculture.