Hyperparameters in Machine Learning
In this article, we will learn about Hyperparameters in Machine Learning. Let’s start!!
Hyperparameters in Machine Learning
A model’s behavior is controlled via hyperparameters, which are fine-tuners or settings. A parameter whose value is chosen in advance of the machine learning process is referred to as a hyperparameter.
It is to be noted that parameters and hyperparameters are not the same thing. The label parameter in machine learning is used to specify those variables the values of which are learned at the time of training.10
Before training starts, it is crucial to select the appropriate hyperparameters because this kind of variable directly affects how well the eventual machine learning model performs.
Hyperparameters regulate the algorithms’ topology and degree of complexity. Therefore, prior to actually fitting ML models to a data set, hyperparameters must be carefully chosen.
The importance of hyperparameters include the fact that algorithm hyperparameters influence both the speed as well as learning mechanism. Hyperparameters are crucial as they can significantly affect the efficiency of the model being trained as well as the behavior of the training algorithm.
The learnt model is significantly impacted by the hyperparameter selection, which is essential to the success of neural network design. In order to control how algorithms learn and alter the effectiveness of the model, machine learning engineers may use hyper-parameters, which are basically variables with specific values.
Examples of Hyperparameters of different ML models
| Algorithm | Hyperparameters |
| Support Vector Machine (SVM) |
|
| K- Nearest Neighbor (KNN) |
|
| Random Forest |
|
| Elastic Net (glmnet) |
|
| Decision Tree |
|
| Gradient Boosting |
|
ML Hyperparameters categorization
Hyperparameters generally have two categories based on the purpose for which they are being used.
1. Hyperparameters for optimization (Hyperparameter Tuning)
Hyperparameter tuning and hyperparameter optimization are terms used to describe the process of choosing the optimum hyperparameters to utilize. To optimize the model, optimization parameters are applied.
The process of hyperparameter tuning entails determining a set of hyperparameter values which are optimal for a learning algorithm and then using this improved algorithm on each given dataset. The model’s performance is maximized by using that set of hyperparameters, which minimizes a predetermined loss function and resulting in better outcomes with minimal errors.
There are two types of hyperparameter tuning:
a. Manual tuning of hyperparameters
Manually experimenting with various sets of hyperparameters using the approach of trial and error is known as manual hyperparameter tuning. Each trial’s outcomes are recorded and utilized as feedback to get the set of hyperparameters that will produce the best model performance.
b. Automated tuning of hyperparameters
An algorithm is used to find the optimal hyperparameters set in automated hyperparameter tuning. In order to determine the best collection of hyperparameters for the model, an automatic hyperparameter tuning strategy uses methods in which the user specifies hyperparameter range or combinations for each hyperparameter.
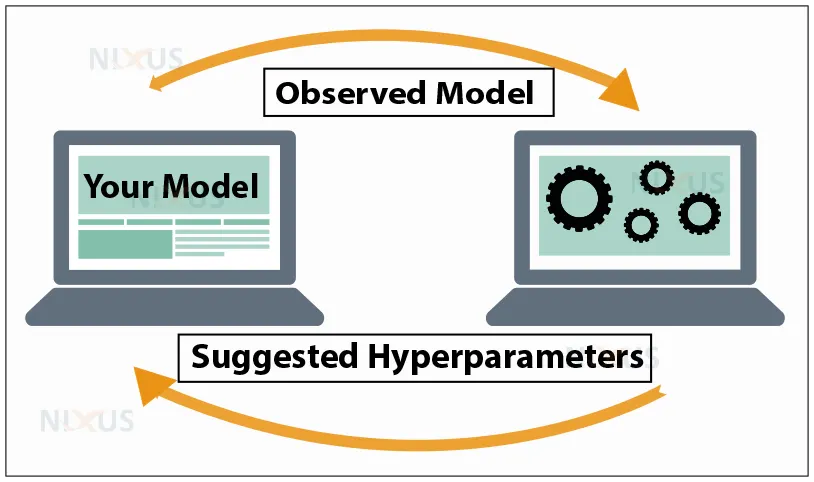
Optimization parameters include:
a. Learning Rate
The hyperparameter known as the learning rate determines how much the model must change each time its weights are changed in response to the predicted error. It specifies how rapidly a neural network upgrades previously learnt concepts. A desired learning rate is one that is both high enough to allow for quick training and low enough to ensure that the network propagates toward something useful.
More time to training is required for a smaller learning rate as in each update, smaller modifications were made to the weights. In case of larger learning rates rapid changes occur and hence require less training time (training epochs). Larger learning rates, however, frequently lead to an ultimate set of weights that is less than ideal.
b. Batch Size
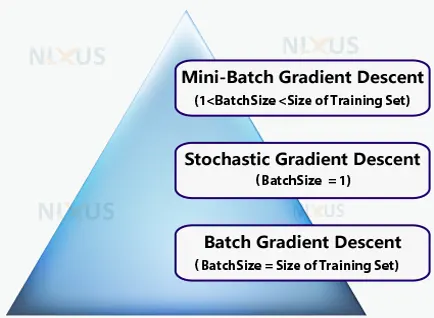
The batch size hyperparameter specifies how many samples must be processed before the internal model parameters are updated. It is possible to separate a training dataset into one or more batches.
The learning algorithm is referred to as batch gradient descent when all training data are combined into a single batch. The learning method is referred to as stochastic gradient descent when the batch size is one sample. And, The learning algorithm is known as mini-batch gradient descent when there are more than one sample in the batch and also, when it is smaller than the size of the training dataset.
c. Epochs
A hyperparameter called “epochs” determines how many times the learning algorithm will run over the whole training dataset. One epoch indicates that the internal parameters of the model have had a chance to be updated for each of the samples in the training set.
One or perhaps more batches make up an epoch. For example, the term “batch gradient descent learning algorithm” refers to an epoch with a single batch.
One can choose an integer value for the number of epochs ranging from one to infinity. The process can be run indefinitely and even be stopped by criteria other than a predetermined number of epochs, for example a change in model error over some time period.
2. Hyperparameters for specific models
The term “hyperparameters for certain models” refers to those hyperparameters that are involved in the model’s structure. Such hyperparameters include:
a. Hidden Units
Between the algorithm’s input and output, a hidden layer is present in neural networks. In this layer, the function gives the input weights and sends them via an activation function as the algorithm’s output. In general, the network’s inputs are transformed nonlinearly by the hidden layers. The neural network’s hidden layers can vary based on how it performs, and in the same way, the layers could also differ based on the weights they are associated with.
Note that, it is very crucial that the number of hidden units hyperparameters be specified for the neural network. More exactly, the number of hidden units must equal 2/3 of the size of the input layer plus the size of the output layer.
Although hidden layers are frequently used in neural networks, their architecture and application can differ depending on the case. Let’s take CNN for object detection in which a hidden layer identifies objects from an image but to detect the number of people out of the whole bunch of objects, a hidden layer put in alliance with additional layers will do the task.
Here, the set of conjunction of hidden layers and other added layers would identify only people from that image. Neural network would get each object and look for types of bodies, position, height of the objects to make predictions and identify all possible people from visual data.
b. Layers
Layers are the term for the vertically stacked components that make up a neural network. Input, hidden, and output layers are primary layers. Neural network with 3 layers performs better than a network with 2 layers. A Convolutional Neural network model performs better with a large number of layers.
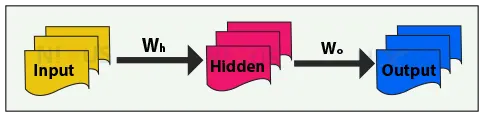
- Input layer: It contains data that will be used to train your model. Each input layer neuron for the dataset corresponds to a distinct property in it.
- Hidden layer: Every neuron in a hidden layer takes inputs from all the neurons in the layer before it and forwards its output to the next layer’s each neuron.
- Output Layer: It is the last layer of a network. It takes input from the preceding hidden layer, may or may not apply an activation function, and then generates an output that represents the prediction made by the model.
Conclusion
An essential component of any modern machine learning pipeline is hyperparameters. The values assigned to the model before training it on any data are known as the model’s magic numbers- “hyperparameters”. It must be implemented properly though in order to get speed improvements.