Machine Learning Algorithms
The concept of machine learning is essentially learning from past experience or observation, such as precedents, or instructions, to seek for trends in input and with the assistance of illustrations, supplied the computer can make better judgments. The main goal of ML is to teach computers to learn on their own without human involvement and to change their behavior appropriately. In this article, we will focus on different algorithms of machine learning and how they are classified.
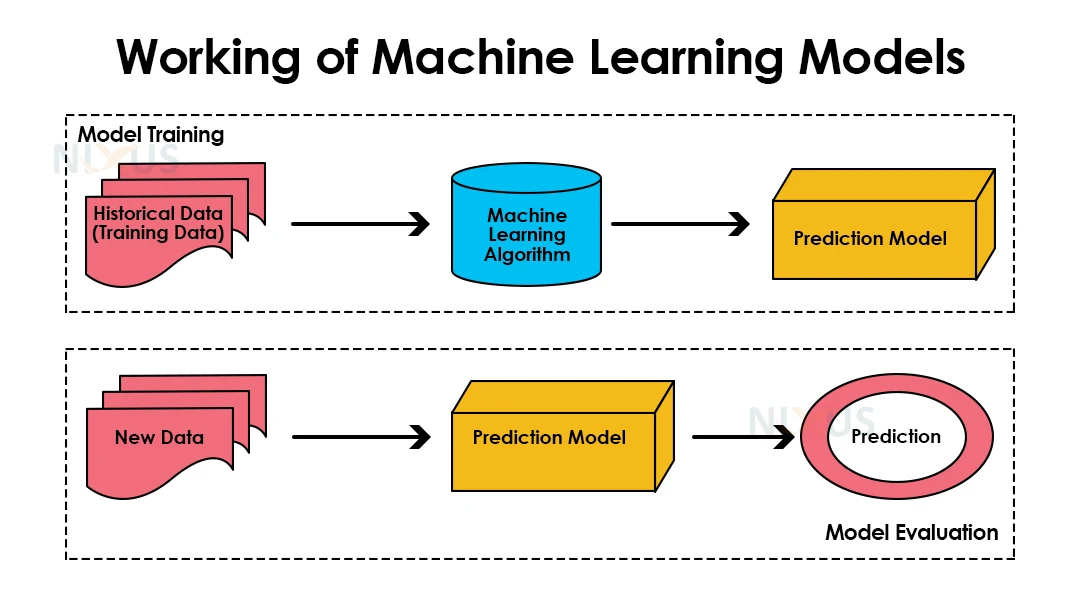
Working of machine learning models
We use past data to train the model, and evaluate the model on fresh data and predict outcomes. We can assess the efficiency of the trained ML model using a subset of the available historical data (which is not present during training). This is commonly known as the validation procedure. Accuracy measures the ML model’s performance over unknown data by dividing the number of properly predicted features by the total number of available features to be predicted.
Machine learning Algorithms by learning style:
Based on its interaction with data or the production environment, a model can describe an issue in a number of ways. There are only a few major learning styles or learning models that an algorithm may have and they are explained below.
1. Supervised Learning:
The training process involves input data that has a predefined label or consequence, such as spam/not-spam or a stock price at a given time.
In training, a model makes predictions and receives corrections when those predictions are incorrect. The model undergoes training until it reaches the appropriate degree of accuracy on the training data.
Classification and regression are two examples of problems. Logistic Regression and the Back Propagation Neural Network are two examples of algorithms.
2. Unsupervised learning:
The input has no labels or predetermined outcomes.
An algorithm derives patterns from the incoming data. This might obtain generic patterns via a statistical procedure to consistently decrease redundancies, or by organizing data by pattern.
Clustering and association rule learning are some examples of tasks. The Apriori algorithm and K-Means are two examples of algorithms.
3. Semi-supervised learning:
The input data consists of both labeled and unlabeled instances.
There is a desirable prediction problem, but the model must learn the structures in order to arrange the data and produce predictions.
Classification and regression are two examples of difficulties.
Exemplification algorithms are expansions to previous flexible approaches that make assumptions about how to describe data with no labels.
4. Reinforcement learning:
Reinforcement learning is a machine learning approach that allows an agent to determine the appropriate future action depending on the current state by acquiring behaviors that maximize reward.
Typically, reinforcement learning systems learn optimum actions through trial and error. Consider a computer game in which the gamer must travel to specific locations at specific times to accumulate points. A reinforcement algorithm playing that game would begin by moving randomly, but through trial and error, it would eventually learn where and when to move the in-game character to maximize its point total.
Machine Learning Algorithms by similarity:
Algorithms are frequently classified based on their functional similarities (how they work). This, I believe, is the most helpful way to organise algorithms, and that is the one we shall apply here.
This is an effective grouping strategy, however, it is not without flaws. There are still algorithms that may be classified as belonging to more than one category, such as Learning Vector Quantization, which is both a neural network-inspired technique and an instance-based method. There are additional similar-sounding categories that characterize the issue and the class of method, such as Regression and Clustering.
1. Regression:
Regression deals with modeling the connection between variables, which is repeatedly refined using an error measure in the model’s predictions.
The most popular regression algorithms are:
- Ordinary Least Squares Regression (OLSR)
- Linear Regression
- Logistic Regression
- Stepwise Regression
- Multivariate Adaptive Regression Splines (MARS)
- Locally Estimated Scatterplot Smoothing (LOESS)

2. Instance-based:
A decision-making process containing instances or examples of training data that are essential or necessary by the algorithm is an instance-based learning method.
The most popular instance-based algorithms are:
- k-Nearest Neighbour (kNN)
- Learning Vector Quantization (LVQ)
- Self-organizing Map (SOM)
- Locally Weighted Learning (LWL)
- Support Vector Machines (SVM)

3. Decision trees:
Decision tree approaches build a model of decisions based on the actual values of characteristics in data.
In tree architectures, decisions fork until a forecast choice is reached for a specific record.. Decision trees are popular in machine learning because they are frequently quick and accurate.
The most popular decision tree algorithms are:
- Classification and Regression Tree (CART)
- Iterative Dichotomiser 3 (ID3)
- Chi-squared Automatic Interaction Detection (CHAID)
- Decision Stump

4. Bayesian:
Bayesian approaches are those that use Bayes’ Theorem directly to solve issues like classification and regression.
The most popular Bayesian algorithms are:
- Naive Bayes
- Gaussian Naive Bayes
- Multinomial Naive Bayes
5. Clustering:
Modeling approaches like centroid-based and hierarchical clustering commonly structure clustering procedures. All approaches utilize the underlying structures in the data to effectively arrange the data into groups with the greatest degree of similarity.
The most popular clustering algorithms are:
- k-Means
- k-Medians
- Expectation Maximisation (EM)

6. Association rule mining:
Approaches for extracting rules that best describe observed associations between variables in data are known as association rule learning methods.
These guidelines can help an organization uncover meaningful and economically useful correlations in huge multidimensional datasets.
Some very popular examples of the said algorithm are:
- Apriori algorithm
- Eclat algorithm

Machine Learning Algorithm examples:
1. Linear regression:
We have a collection of input parameters (x) from which an output is determined (y). There is a connection between the input data and the result. The purpose of machine learning is to measure this link.
The link in Linear Regression has an equation as follows: As a result, the purpose of linear regression is to determine the values of coefficient a and slope b.
The aim is to choose a line that is closest to the majority of the points.
2. Logistic regression:
Logistic Regression is a method for estimating discrete values (often binary values such as 0/1) from a set of independent variables. It predicts the likelihood of an occurrence by fitting data to a logit function.
These strategies frequently enhance logistic regression models:
- include phrases for interaction
- Remove characteristics
- Use non-linear models in regularisation procedures.
3. Decision Tree:
The Decision Tree method in machine learning is one of the most popular algorithms today; it is a classification method for issue classification. It is effective at categorising both categorical and continuous dependent variables. We divide the population into two or more homogenous sets using this approach based on the most significant attributes/independent variables.
4. SVM (Support Vector Machine) Algorithm:
This algorithm depicts data items as points in n-dimensional space with n being the number of features of the dataset. The value of each character has a specific point, making it simple to categorize the data. Classifier lines can separate data and plot it on a graph.
5. Naive Bayes Algorithm:
A Naive Bayes algorithm assumes that anyone feature is entirely independent of any other feature in the dataset.
Even though these characteristics have mutual connections, a Naive Bayes classifier would analyze all of them independently while determining the likelihood of a certain result.
A Naive Bayesian model is simple to construct and good for large datasets. It’s easy to use and has been shown to outperform even the most advanced categorization systems.
6. Random Forest Algorithm:
We can describe a random forest best as a group or a collection of decision trees. Each item in a tree is in a category, and the tree “votes” for that category, in order to categorise a new item using its properties. The forest chooses the categorization with the highest votes.
Each tree is planted, created and cultivated in the following manner:
If the number of instances in the training set is N, a random sample of N examples is chosen. This sample will serve as the training set for the tree’s growth.
If there are M input variables, a number m value of m is kept constant throughout the operation.
Each tree is grown to the greatest degree possible. There will be no pruning.
7. K-Means:
It is a problem-solving unsupervised learning method. We group data sets into a specific number of clusters (let’s call that number K) in such a way that all of the pieces of data inside a cluster are homogeneous and heterogeneous with respect to the data in other clusters.
How K-means generates clusters:
- The K-means method selects k centroids (points) for each cluster.
- Each data point creates a cluster with the nearest centroids, resulting in a total of K clusters.
- It now generates new centroids depending on the members of the existing cluster.
- It then computes the closest distance for each data point using these updated centroids. We repeat this procedure until the centroids remain constant.
8. KNN (K- Nearest Neighbours) Algorithm:
This approach is useful for both classification and regression issues. It appears to be more extensively utilised in the Data Science business to tackle categorization challenges. It’s a straightforward algorithm that maintains all existing examples and classifies any new cases based on a majority vote of its k neighbours. The case is then allocated to the class that has the most in common with it. This measurement is carried out via a distance function.
9. Linear Discriminant Analysis:
The Linear Discriminant Analysis method is the preferred linear classification technique when there are greater than two major groups.
LDA is represented in a simple manner. It is made up of statistical characteristics computed from your dataset for each group.
Computing a discriminating value for each class and producing a forecast for the class with the highest value is how predictions are created. Because the approach presupposes that the input has a Gaussian distribution (bell curve), it is best to eliminate anomalies from your dataset first. It is a straightforward and effective strategy for solving classification predictive modelling challenges.
10. Apriori:
In a transactional database, the Apriori algorithm can mine frequent item sets and subsequently construct association rules. It is commonly employed in market basket analysis, where one looks for product combinations that regularly co-occur in the database. In general, the association rule for ‘if a person buys item X, then he buys item Y’ : X -> Y.
The Support measure aids in the reduction of the number of candidate item sets to be evaluated during frequent item set production. The Apriori principle guides this support measure. According to the Apriori principle, if an itemset is frequent, then all of its subsets must likewise be frequent.
11. Principal Component Analysis:
PCA primarily reduces the amount of variables in data to make it easier to examine and display. We do this by collecting the largest variation in the data and storing it in a new co – ordinate system with axes known as ‘principal components.’
Each component is orthogonal to the others and is a linear combination of the original variables. The presence of orthogonality between components means that there is no correlation between them.
12. CART:
Classification and Regression Trees (CART) are one type of Decision Tree application.
Trees have two sets of nodes: the root node and the internal node. The leaf nodes are the terminal nodes. Each non-terminal node represents a single input variable (x) and its splitting point; the leaf nodes represent the output variable (y). To produce predictions, the model is as follows: walk the tree splits to reach a leaf node and output the value present at the leaf node.
13. Gradient Boosting Algorithm and AdaBoosting Algorithm:
These are boosting techniques that are employed when large amounts of data must be processed in order to create accurate predictions. Boosting is an ensemble learning approach that improves resilience by combining the predictive ability of numerous base estimators.
In a nutshell, it combines many poor or mediocre predictors to create a powerful one. These boosting algorithms consistently do well in data science contests like as Kaggle, AV Hackathon, and CrowdAnalytix. These are the most popular machine learning methods right now. Use them in combination with Python and R programmes to produce correct results.
Summary:
This article was an introduction to machine learning algorithms. I did outline and explain types of grouping, the logic behind it as well as some example algorithms. However, due to the vastness of the field, I was unable to cover everything. I did not cover specialised algorithms like Feature selection algorithms or field-focused ones like Computational intelligence (evolutionary algorithms, etc.) or graphical models.