Movie Recommendation using Collaborative Filtering
With this Machine Learning Project, we will be building a movie recommendation system. The movie Recommendation system is used by all OTT platforms nowadays. As the name suggests itself that this system will recommend movies to users.
So, let’s build this recommendation system in this project using collaborative filtering.
Movie Recommendation System
So, what is this Movie Recommendation System?
A movie recommendation system is a system that will predict the movies that we are very likely to watch based on our past history of watching movies. Recommendation Systems can be used in any field like e-commerce website to suggest products for a user to buy, or books that the user should read.
This movie Recommendation system is used by OTT platforms to suggest movies to users based on the ratings given by users. Using this system, these OTT platforms are able to suggest us good movies that we are very likely to watch and this made our experience better.
Collaborative Filtering
So, what is this collaborative filtering anyway?
Well, there are two ways to implement the recommendation system. One is using content-based filtering and the other is collaborative filtering.
Content-Based Filtering – In this, we train the recommendation system in a way that it suggests the movies based on the content that he likes in the past. Suppose, if a user watches an action movie and gave it a 5-star rating, then our system will suggest him more action movies.
Collaborative Filtering – In this, we train the recommendation system in a way that it suggests the movies based on what other users have liked. The system will try to find similarity between the user who watches the same kind of movies.
For example – suppose two users who watch the same movie say ‘action1’ in the past and they both liked it and gave it a 5-star rating. So our system will see that these users may like the same kind of movies. So, if the first user sees a movie that says ‘action2’ then it will be recommended to the second user as well.
We will use Pearson Method to find the similarity between the two users. We will see it later on.
Pearson Method
Pearson’s method allows you to find the degree of similarity between two variables. It works in the same way Euclidean distance works. Like Euclidean distance finds the distance between two points. In the same way, pearson method will find similarities between the two variables.
We are using Pearson Method in this because it gives more accurate results than Euclidean distance.
Below is graph of Pearson model for close and far similarity.

Pearson Method gives the result between -1 to 1.

This is the formula for Pearson. But we don’t need a formula because there is an inbuilt method for this task.
The Model Architecture
The model we built is a collaborative filtering matrix. The matrix is created using the Pearson method (discussed above) by calculating the similarity between users.
After that, we provide a movie and rating (whether we like the movie or not) to the model and it will suggest to me movies that I might like.
Let’s understand this more clearly with an example –
Suppose a user ‘A’ watches a movie and likes it and gives a rating of 5. So our model will store this information and will use this to find recommendations for him. This movie and its rating will be used by the model to find suggestions for the user. Our model will perform some calculations to find similar movies. In the calculation, it will multiply the rating with the similarity score of movies calculated using the Pearson method. Then it will sort the movie score we get in Descending order. It will then return the movie list.
The movie with the highest score will be suggested to the user on top followed by all the movies.
Project Prerequisites
The requirement for this project is Python 3.6 installed on your computer. I have used google colab notebook for this project. You can use whatever you want.
The required modules for this project are –
Pandas – pip install pandas
That’s all we need for our recommendation. All the things that we need are there in the panda’s module.
Movie Recommendation Project
The datasets are in CSV files and there are two different CSV files. One is named Movies.csv which contains the name and genre of the movies. The other is Ratings.csv which contains the ratings given different movies given by different users. Please download movie recommendation machine learning code and dataset from the following link: Movie Recommendation Project
Steps to Implement Movie Recommendation Project
1. Import the Modules and read the movies and rating CSV file.
import pandas as pd
ratings = pd.read_csv('dataset/ratings.csv')
movies = pd.read_csv('dataset/movies.csv')
ratings.head()
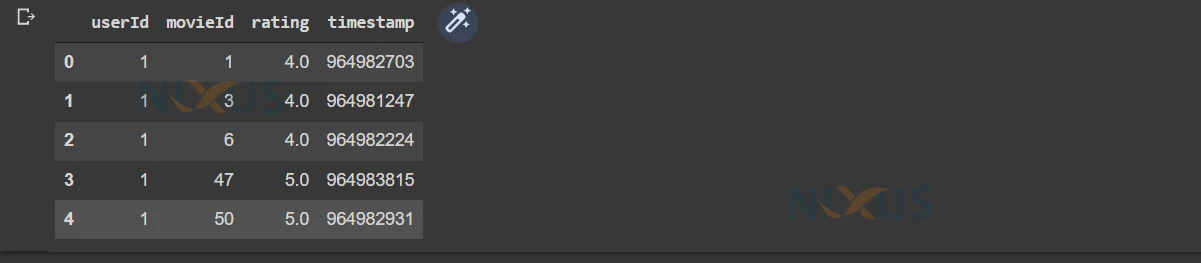
2. Merge the rating and movies files together using Pandas in one file.
ratings = pd.merge(movies,ratings) ratings.head()
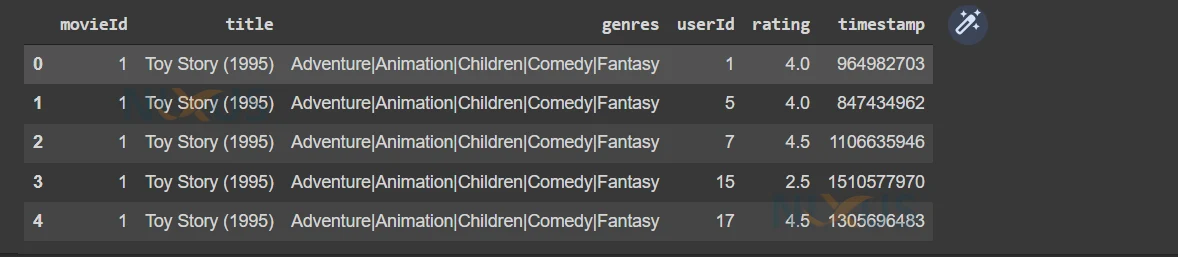
3. Here We removed the genres and timestamp columns from our dataset. These columns were totally useless in collaborative filtering because we are suggesting the movies based on similarities between the users.
ratings = ratings.drop(['genres','timestamp'],axis=1) ratings.head()

4. Here we are creating a matrix with rows as names of movies and columns as users for a more clear view. The values of the matrix are the ratings. So, we read the given matrix as – the ratings given by a user ‘x’ to a movie ‘y’.
user_ratings = ratings.pivot_table(index=['userId'],columns=['title'],values='rating') user_ratings.head()
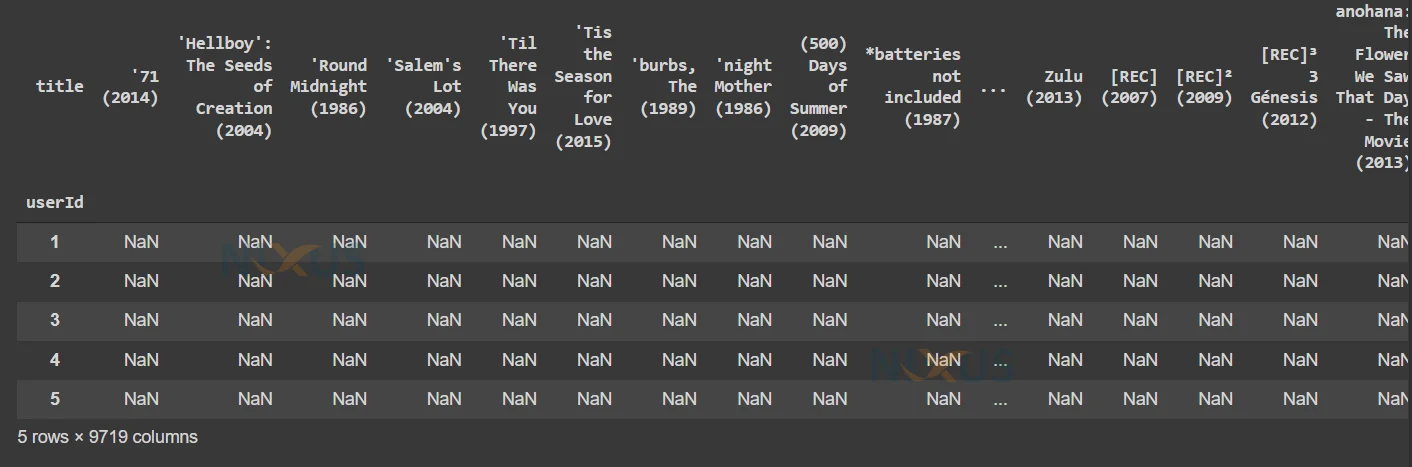
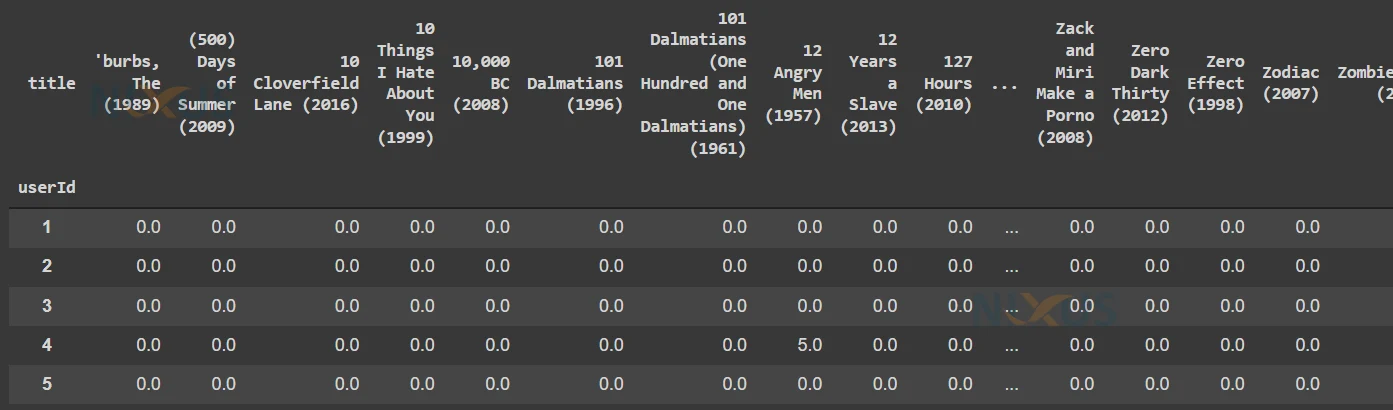
5. Here we are removing some of the movies that are rated by very few users. We removed them to clean the dataset. For the rest of the movies, which are rated by most of the users but there are some null values in that movie column, we will fill it with 0.
## There must be a lot of movies which are rated by very few users. So we need to remove them user_ratings = user_ratings.dropna(thresh=10,axis=1).fillna(0) user_ratings.head()
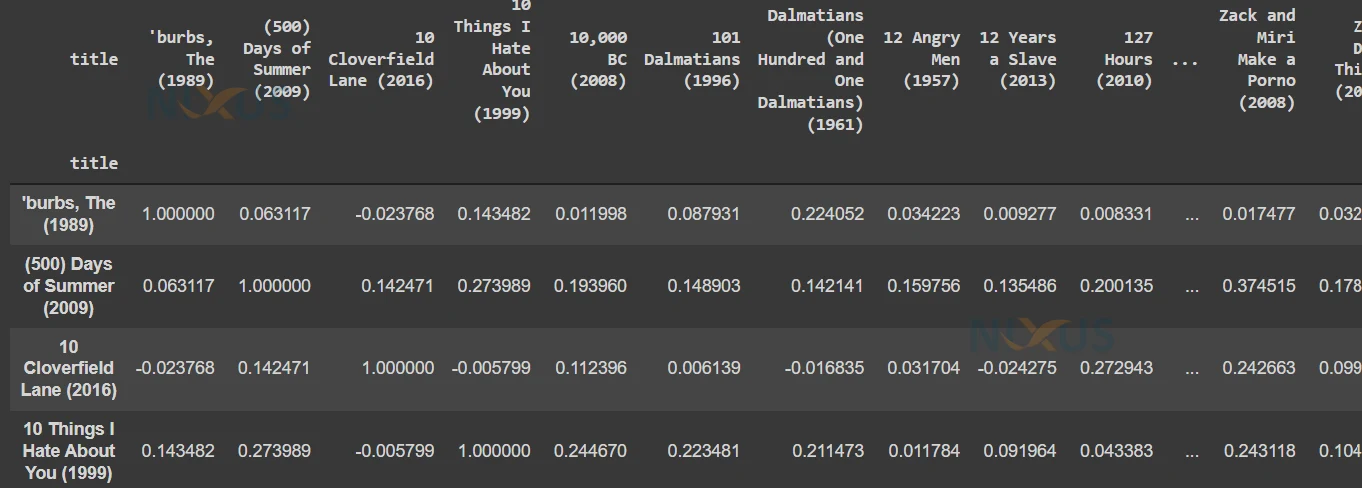
6. Here we are using “Pearson” method to build a similarity matrix. This similarity matrix can be read as – for a particular row, how much it is similar to all the movies in terms of ratings given by the users. Like – how much “(500) Days of Summer” is similar to “burbs, the (1989)” or “10 cloverfield Lane (2016)”.
This matrix gives us a correlation of a movie with all the movies.
## Let's Build our Similarity Matrix item_similarity_df = user_ratings.corr(method='pearson') item_similarity_df.head(50)
7. Here we are making a get similar movie function which will return the movies similar to the movie provided by us.
So, this function takes two arguments movie name and user rating. Suppose we are supposed to suggest movies to a user. And suppose he watches a movie and liked it and gave it a rating of 5. Now we are supposed to give him suggestions. To do this, we are multiplying the rating given by the user by the score that we calculated in the previous step and sorting it in ascending order.
### Let's write method to return similar movies
def get_similar_movies(movie_name,user_rating):
similar_score = item_similarity_df[movie_name]*(user_rating-2.5)
similar_score = similar_score.sort_values(ascending=False)
return similar_score
get_similar_movies("'burbs, The (1989)",4)
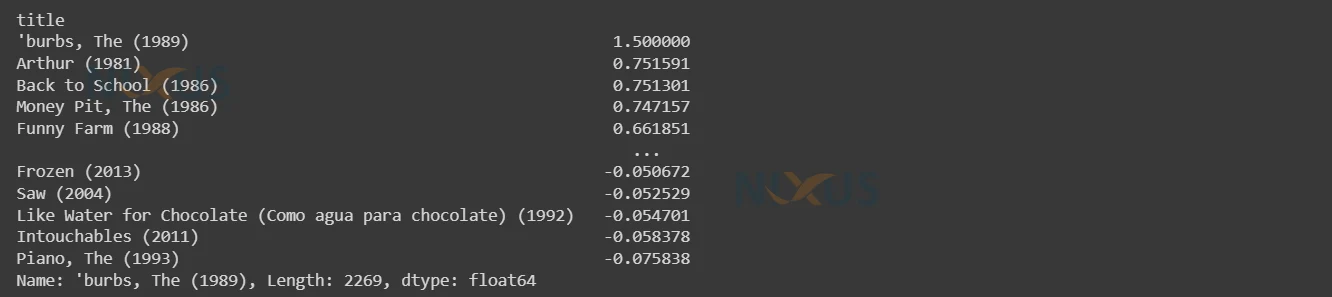
8. Here is the result.
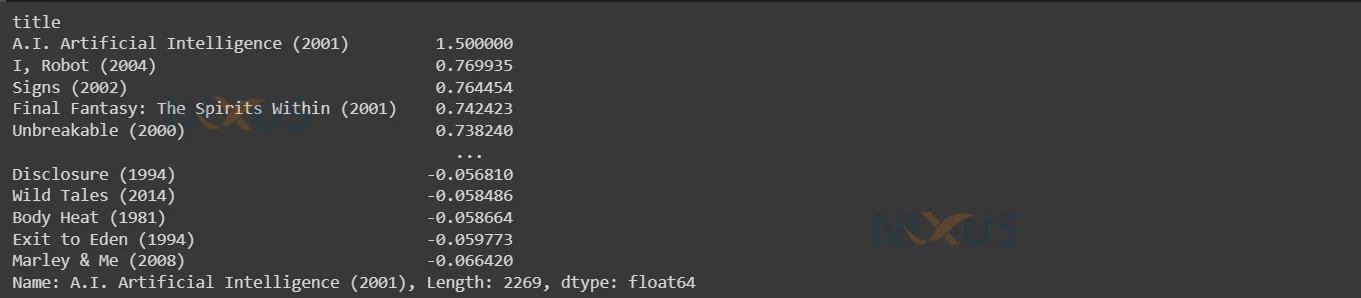
get_similar_movies("A.I. Artificial Intelligence (2001)",4)
Movie Recommendation Output
Summary
In this Machine Learning project, we built a movie recommendation system. We used collaborative filtering in our system and used the Pearson method to find the correlation between users. We hope you learn what is recommendation system and how it works.