Supervised Learning Types, Algorithms and Applications
In today’s article, we will learn about Supervised Machine Learning, its working, types, algorithms, applications etc. Let’s start!!
What is Supervised Learning?
Machine learning allows a machine to learn from data, improve performance based on previous experiences, and make predictions. Machine learning is a collection of algorithms that deal with massive amounts of data. We supply data to these algorithms to train them, and the model is built and a certain job is performed based on the training.
Supervised learning is a subtype of machine learning where we can teach algorithms with well-labeled training data and then infer the result based on that information. In this context, labeled data means that part of the data input has already been labeled with the appropriate output.
In supervised learning, it is similar to having a teacher teach the model. Supervised learning models need users to supply both input and sample output data. A supervised learning algorithm’s goal is to discover a mapping function that will translate the input variable(x) to the output variable(y).
Working of supervised learning models
- Gather, collect and label data. Can also use pre-tagged data with these models.
- We divide the dataset into three parts: training dataset, test dataset and validation dataset.
- Determine the dataset’s input features so that they include enough data to make accurate interpretations.
- Choose an appropriate algorithm for the model, such as a support vector machine or a decision tree.
- Use the training dataset to run the algorithm. Validation sets, which are a subset of training datasets, are sometimes required as control parameters.
- Evaluate model accuracy with the testing set.
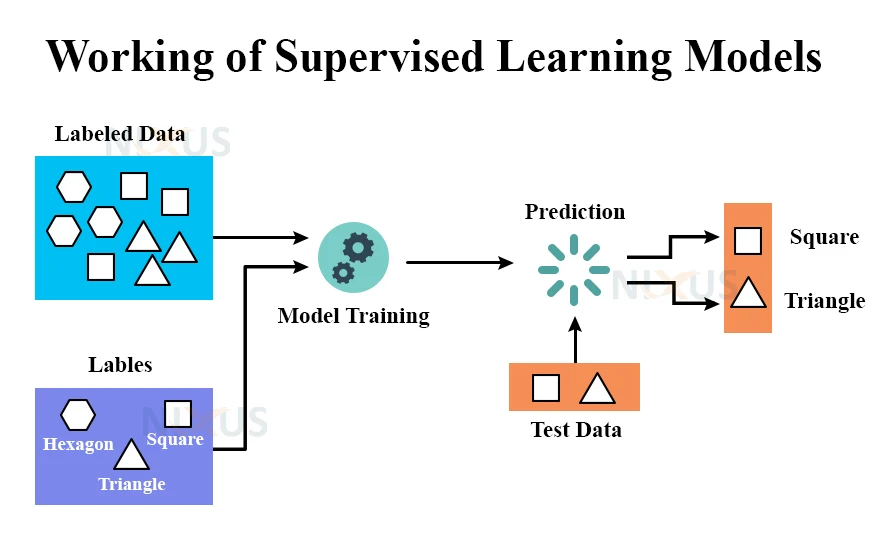
From the diagram, we can see that we provide the model with data (shapes) and their labels (corresponding names). The model trains itself on this data. To test if the model has been properly trained, we provide data with no labels. The model predicts the labels (names) of the test data (shapes).
Types of Supervised Learning
We can classify supervised learning further into 2:
1. Regression:
If there is a link between the input and output variables, we apply regression procedures. It’s useful to predict continuous variables like weather forecasts, market trends, and so on.
2. Classification:
There are a few possible output values and they are categorical. Example: true-false, male-female-other etc
Supervised Learning algorithms:
1. Naive Bayes:
This method is most common for text categorization, spam detection, and recommender systems.
The Bayes Theorem’s premise of conditional independence is applicable in the Naive Bayes classification technique. This indicates that the existence of one component has no influence on the existence of another in the probability of a certain event, and each predictor feature has the same effect on that result. That is, no two features are connected or dependent on each other.
Multinomial Naive Bayes, Bernoulli Naive Bayes, and Gaussian Naive Bayes are the three kinds of Naive Bayes classifiers.
2. Linear regression:
Linear regression is widely useful to determine future events by identifying the link between a dependent measure and one or more independent variables. We can use basic linear regression when there is only one independent factor and one dependent variable. We use multiple linear regression when the number of independent variables rises. It aims to depict a line of greatest fit, using the least squares approach, for each kind of linear regression. However, like other regression models, when shown on a graph, this line is straight.
3. Logistic regression:
Although linear regression is applicable when the dependent variable is continuous, one can use logistic regression when the dependent variable is categorical, which means it has binary outputs such as “0” and “1”. Although both regression models attempt to discover correlations among data inputs, logistic regression is mostly employed to address binary classification issues such as spam detection.
4. Support vector machine:
A support vector machine is a common supervised learning model designed by Vladimir Vapnik that we use for data categorization as well as regression. However, it is largely applicable for classification issues, building a hyperplane with the greatest gap between two categories of data points. This hyperplane is the decision boundary, and it separates data point classes (e.g., oranges vs. apples) on either side.
5. Random forest:
Random forest is also another versatile supervised machine learning technique that is useful for classification and regression. The term “forest” refers to a set of statistically independent decision trees that are subsequently blended to minimize variation and produce more precise data predictions.
Applications of supervised learning:
1. Image and object recognition:
Supervised learning methods find, separate, and categorize items in movies or pictures, rendering them helpful for a variety of computer vision and imaging analysis approaches.
2. Predictive analytics:
Creating predictive analytics systems enables businesses to predict certain outcomes depending on a particular output variable, assisting business executives in justifying actions or pivoting for the organization’s advantage.
3. Customer sentiment analysis:
Companies can retrieve and categorize crucial bits of information from vast amounts of data—including contextual information, sentiment, and intent—with very little human interaction using supervised machine learning algorithms. This may be quite beneficial in terms of having a better knowledge of consumer interactions and improving brand engagement initiatives.
4. Spam detection:
Spam detection is a supervised learning algorithm that identifies emails from spammers. Companies may train systems to recognize patterns or abnormalities in fresh data using supervised classification techniques, allowing them to efficiently categorize spam and non-spam email exchanges.
Advantages of supervised learning
- Supervised learning models learn from experience.
- These models have an accurate idea of classes and categories in the dataset owing to training
- Can handle a variety of real-world issues
Disadvantages of supervised learning
- Cannot handle difficult, complex or demanding problems efficiently
- If the test data differs from the training data, supervised learning will not be able to predict the proper output.
- Training necessitated a significant amount of computing time and resources
Summary
In Supervised learning techniques, you train the system using well-labeled data. A Supervised Machine Learning method has two dimensions: regression and classification. The difficulty in supervised learning is because irrelevant input features in training data might lead to erroneous outcomes. The fundamental benefit of supervised learning is that it allows you to gather data or generate data output from past experience.
thank you for this tutorial